

概要
TypeScript版のLangChainを用いて、独自データを使って回答してもらう方法を解説する😊
今回作るもの
- 名探偵コナンの映画「⿊鉄の⿂影」についての答えてくれるプログラムを作成する。
- 上記データはPDFファイルとしてまとめたものを使う。
- 画面は作らない。コマンドで実行する。

LangChainのバージョン
✅安定版のv.0.1.25時点のコードで解説する。
- 2023/05/13作成:v0.0.121のコードを記載。
- 2024/03/08更新:v.0.1.25(安定版)のコードを追記。
LangChainとは
LLM(大規模言語モデル)を強化できるライブラリ✅
LangChainで独自データを使うには
独自データを使う手順
- ファイルを読み込む。
- 読み込んだ文章を分割する。
- 分割した「文章」を「数字の羅列」に変換する。
- 「数字の羅列」を専用のデータベースに保存する。
- 専用のデータベースから、質問文に関連するデータを検索して回答に使用する。
使用する技術
- Open AIのAPI(有料)
- Node.js
- TypeScript
- TypeScript版のLangChain
環境構築
今回のコードを動かすには事前に「パッケージのインストール」「APIキーの設定」が必要⚠️
こちらの記事のとおりやれば2~3分でできるので、先に設定しておく😊
サンプルを実行してみる
独自データを用意する
回答に使う独自データを用意する✅
主な対応ファイル形式
- CSV
- docx
- JSON
- JSONLines
- テキスト
- PDF など
対応ファイル形式一覧
対応しているファイル一覧は以下を参照。

Web上のデータを使うこともできる。
ファイルの用意
今回はフォルダの最上階層に名探偵コナンの映画「⿊鉄の⿂影」についてまとめたPDFファイル「document_Conan.pdf」を用意する。
パッケージをインストール
- langchain
- @langchain/openai
- @langchain/community
- hnswlib-node
- pdf-parse
- dotenv
- typescript
npmコマンドでインストールする。
npm install langchain
npm install @langchain/openai
npm install @langchain/community
npm install hnswlib-node
npm install pdf-parse
npm install dotenv
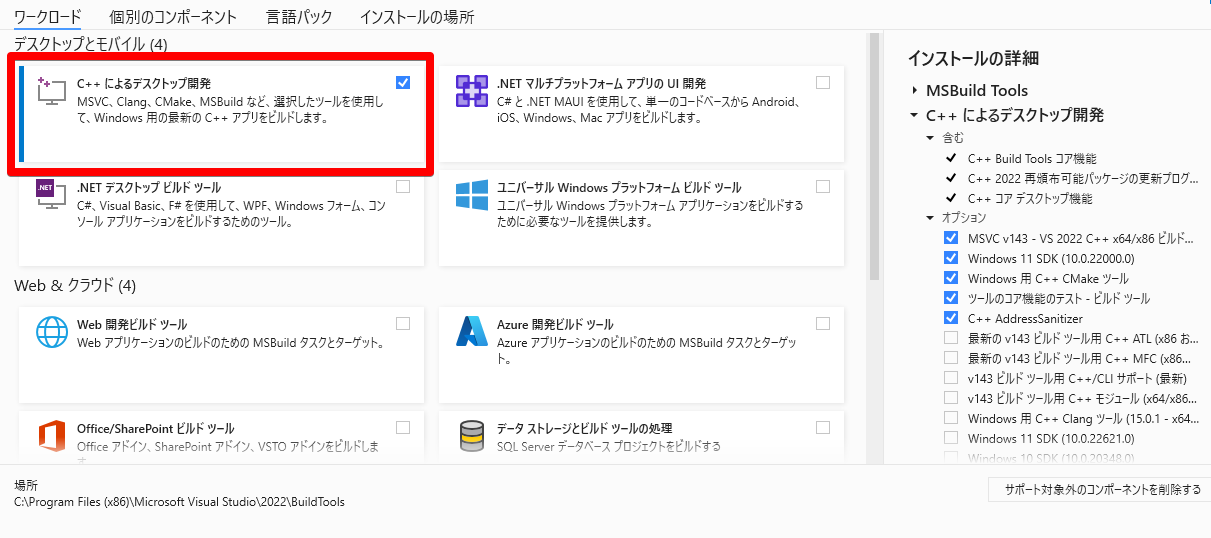
npm install -g typescript【Windowsの場合】Visual Studioが必要
HNSWLibはC++のツールなのでC++をビルドするためにVisual Studioが必要。
(ダウンロードリンク)https://visualstudio.microsoft.com/thank-you-downloading-visual-studio/?sku=BuildTools
ダウンロード後、[C++によるデスクトップ開発]にチェックを付けてインストールすればOK!
APIキーの準備
空の.envファイルを作って、OpenAIのAPIキーを記載しておく。

.env
OPENAI_API_KEY="あなたのAPIキー"TypeScriptを使う準備
以下のコマンドでtsconfig.jsonを生成しておく。
tsc --initサンプルプログラムを作成する(①準備)
まずは独自データからベクトルデータを作成する必要がある。
※開発者が事前に1度だけ行えばOK(独自データ(PDF)は固定のデータなので質問のたびに実行する必要はない)
イメージ(内容は分からなくてもOK)
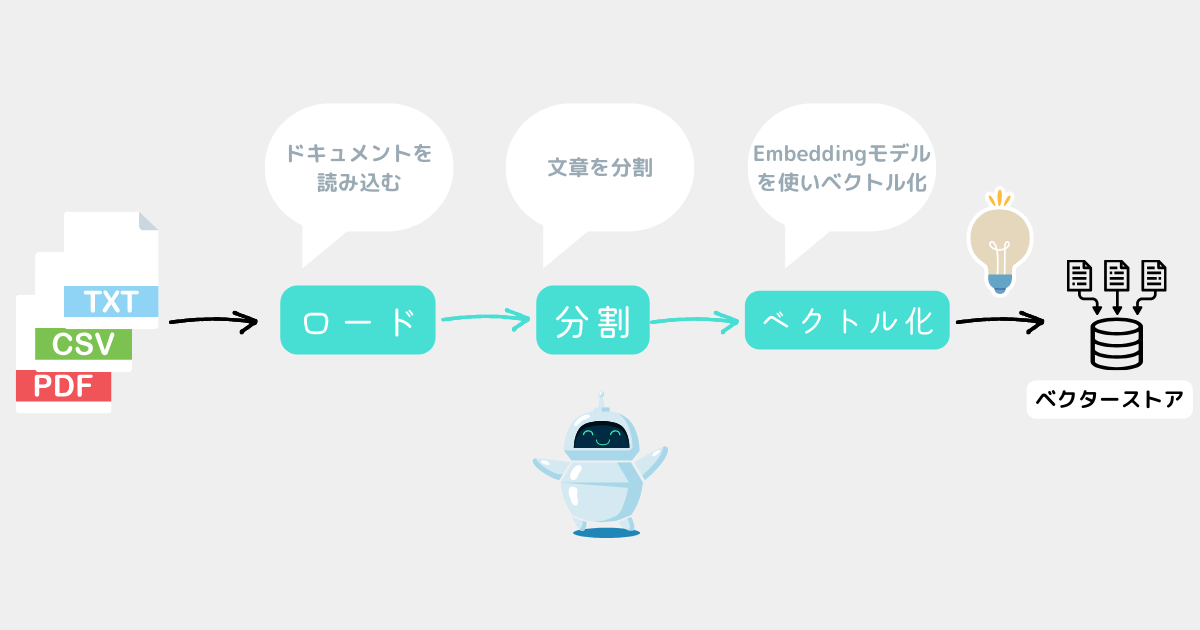
【補足】ベクトルデータの管理にはVector Storeを使う
前提としてベクトルデータとは「独自データ」→「ベクトルデータ(ただの数字)」に変換したもの。
世の中にはベクトルデータ(ただの数字)を保存するためのデータベースが存在する。
これをVector Storeと呼ぶ。
(参考)公式ドキュメント:https://js.langchain.com/docs/integrations/vectorstores/hnswlib
【補足】Vector Storesの種類と選び方
公式ドキュメント(https://js.langchain.com/docs/modules/indexes/vector_stores/)から代表的なものを紹介する。
代表的なベクターストア
| 用途 | 推奨のベクターストア |
|---|---|
| Node.jsアプリ内での実行 | HNSWLib、Faiss、LanceDB、またはCloseVector |
| ブラウザのような環境での実行 | MemoryVectorStoreまたはCloseVector |
| ローカルのDockerコンテナ内 | Chroma |
全ベクターストア
| 用途 | 推奨のベクターストア |
|---|---|
| Node.jsアプリ内での実行 | HNSWLib、Faiss、LanceDB、またはCloseVector |
| ブラウザのような環境での実行 | MemoryVectorStoreまたはCloseVector |
| Pythonからの移行 | HNSWLibまたはFaiss |
| ローカルのDockerコンテナ内 | Chroma |
| ローカルで低遅延 | Zep |
| ローカルまたはクラウドでホスト可能 | Weaviate |
| 既にSupabaseを使用している場合 | Supabaseベクターストア |
| マネージド型でホスティング不要 | Pinecone |
| SingleStoreまたは分散型、高性能データベースを使用している場合 | SingleStoreベクターストア |
| オンラインMPPデータウェアハウジングサービスを探している場合 | AnalyticDBベクターストア |
| SQLを使用したベクトル検索可能なコスト効率の良いベクターデータベース | MyScale |
| ブラウザとサーバーサイドの両方からロード可能 | CloseVector |
| 解析クエリ用に優れたパフォーマンスを発揮するスケーラブルなオープンソースのカラム型データベース | ClickHouse |
プログラムの作成
プロジェクトフォルダの直下に以下のファイルを作成する✅
save_data.ts
// .envの読み込み
require("dotenv").config();
// PDFローダー
import { PDFLoader } from "langchain/document_loaders/fs/pdf";
// テキスト分割
import { RecursiveCharacterTextSplitter } from "langchain/text_splitter";
// 埋め込み
import { OpenAIEmbeddings } from "langchain/embeddings/openai";
// ベクトル検索エンジン
import { HNSWLib } from "langchain/vectorstores/hnswlib";
// サンプル用の関数
export const save_data = async () => {
// ✅ドキュメントの読み込み
const loader = new PDFLoader("document_Conan.pdf");
// ✅PDFファイルを500文字ごとに分割
const textSplitter = new RecursiveCharacterTextSplitter({ chunkSize: 500 });
const docs = await loader.loadAndSplit(textSplitter);
// ✅ドキュメントをベクトル化
const vectorStore = await HNSWLib.fromDocuments( docs, new OpenAIEmbeddings() );
// ✅ベクターストアに保存
await vectorStore.save("MyData"); // MyDataフォルダ
};
save_data();【旧】Ver.0.0.121時点のコード
※上記のコードと同じ。
【解説】ドキュメントの読み込み
// ✅ドキュメントの読み込み
const loader = new PDFLoader("document_Conan.pdf");new PDFLoader(...)でPDFファイルを読み込む。
"document_Conan.pdf"を読み込む。【解説】PDFファイルを500文字ごとに分割
// ✅PDFファイルを500文字ごとに分割
const textSplitter = new RecursiveCharacterTextSplitter({ chunkSize: 500 });
const docs = await loader.loadAndSplit(textSplitter);loader.loadAndSplit()でPDFを分割し、Document型(モデルが扱える形)の配列に変換。- 質問文の文字数には制限がある。
- 質問時にオーバーしないように適度な長さに分割しておく。
【解説】ドキュメントをベクトル化
// ✅ドキュメントをベクトル化
const vectorStore = await HNSWLib.fromDocuments( docs, new OpenAIEmbeddings() );- 「500文字ごとに区切られたデータ
docs」をベクトル化(数字に変換)する。
OpenAIEmbeddingsを使用。【解説】ベクターストアに保存
// ✅ベクターストアに保存
await vectorStore.save("MyData"); // MyDataフォルダsave()でベクトルデータを保存できる。
トランスパイル
TypeScriptをトランスパイルしてJavaScriptファイルを生成する。
以下のコマンドを実行する✅
tsc
サンプルプログラムを実行する
以下のコマンドを実行する✅
node make_index.jsエラーがでなければOK!

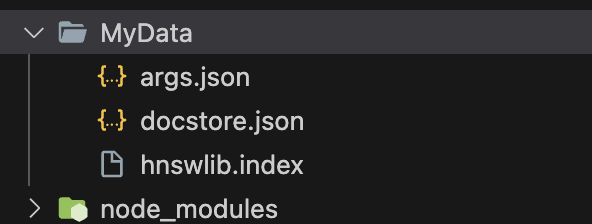
実行するとMyDataフォルダが作られ、中にベクターストアのデータが生成される。
サンプルプログラムを作成する(②質問を実行する)
ここからが本題!
さきほど作ったベクトルデータを使ってAIが回答するプログラムを作っていく。
※ユーザーが質問するときは、このプログラムを実行すればOK!
プログラムの作成
プロジェクトフォルダの直下に以下のファイルを作成する✅
query.ts
// .envの読み込み
require("dotenv").config();
// モデル
import { OpenAI } from "@langchain/openai";
// 埋め込み
import { OpenAIEmbeddings } from "@langchain/openai";
// ベクトル検索エンジン
import { HNSWLib } from "@langchain/community/vectorstores/hnswlib";
// チェーン
import { RetrievalQAChain } from "langchain/chains";
// サンプル用の関数
export const runLlm = async () => {
// ✅作成済みのベクターストアを読み込む
const vectorStore = await HNSWLib.load(
"MyData", // MyDataフォルダ
new OpenAIEmbeddings()
);
// ✅モデル
const model = new OpenAI({}); // OpenAIモデル
// ✅チェーン
const chain = RetrievalQAChain.fromLLM(model, vectorStore.asRetriever());
// ✅質問する
const res = await chain.invoke({
query: "ピンガはどんなキャラクターですか?",
});
console.log({ res });
};
runLlm();【旧】Ver.0.0.121時点のコード
// .envの読み込み
require("dotenv").config();
// モデル
import { OpenAI } from "langchain/llms/openai";
// 埋め込み
import { OpenAIEmbeddings } from "langchain/embeddings/openai";
// ベクトル検索エンジン
import { HNSWLib } from "langchain/vectorstores/hnswlib";
// チェーン
import { RetrievalQAChain } from "langchain/chains";
// サンプル用の関数
export const runLlm = async () => {
// ✅作成済みのベクターストアを読み込む
const vectorStore = await HNSWLib.load(
"MyData", // MyDataフォルダ
new OpenAIEmbeddings()
);
// ✅モデル
const model = new OpenAI({}); // OpenAIモデル
// ✅チェーン
const chain = RetrievalQAChain.fromLLM(model, vectorStore.asRetriever());
// ✅質問する
const res = await chain.call({
query: "ピンガはどんなキャラクターですか?",
});
console.log({ res });
};
runLlm();【解説】作成済みのベクターストアを読み込む
// ✅作成済みのベクターストアを読み込む
const vectorStore = await HNSWLib.load(
"MyData", // MyDataフォルダ
new OpenAIEmbeddings()
);HNSWLib.load()でベクターストアを読み込む。
【解説】モデル
// ✅モデル
const model = new OpenAI({}); // OpenAIモデル- 使用したいモデルを生成する。
OpenAIを使用する。(好きなモデルでOK。チャットモデルChatOpenAIも使用可能。)
【解説】チェーン
// ✅チェーン
const chain = RetrievalQAChain.fromLLM(model, vectorStore.asRetriever());- チェーンに独自データを使うように設定しておく。
- そのために引数にインデックスのレトリーバー(ベクターストアを検索する機能)を指定する。
vectorStore.asRetriever()
RetrievalQAChainを使用する。(好きなチェーンでOK。その他のチェーンはこちら。)
【解説】質問する
// ✅質問する
const res = await chain.invoke({
query: "ピンガはどんなキャラクターですか?",
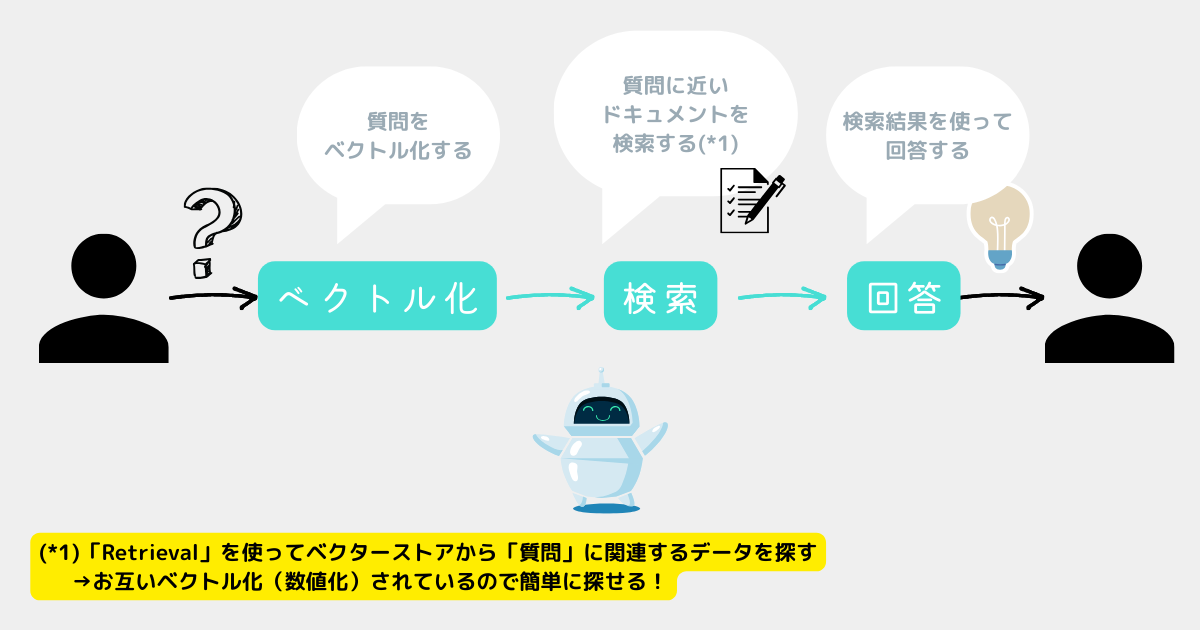
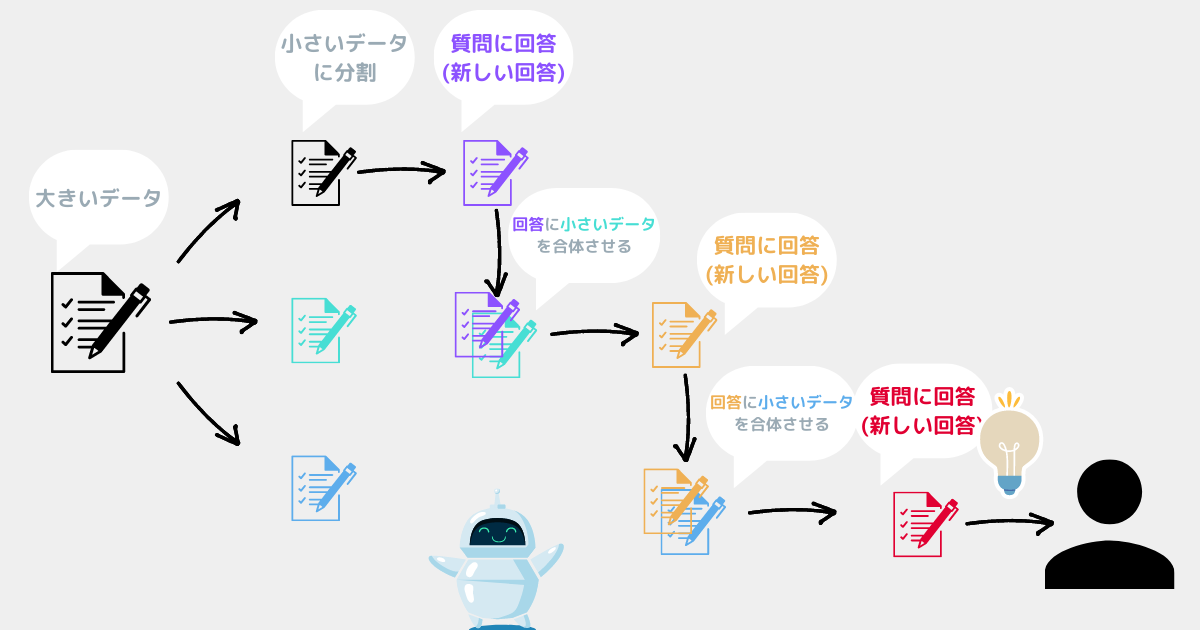
});chain.invoke()で質問できる。- 内部的にはイメージ図のような流れになっている。
トランスパイル
TypeScriptをトランスパイルしてJavaScriptファイルを生成する。
以下のコマンドを実行する✅
tsc
サンプルプログラムを実行する
以下のコマンドを実行する✅
node query.js回答が表示されればOK!

もっと詳しい知識
今回のメインの話はここまで!
以下は興味がある人だけどうぞ😊
各クラスの詳細
より複雑なプログラムを作る場合はクラスの詳細を確認するのがおすすめ✅
APIリファレンスに各クラスで使える関数が詳しく書かれている。
回答の精度を上げる方法
こちらで精度を上げる方法を解説している😊
ベクターストアを使わず独自データに回答してもらう方法
ベクターストアを使わない方法もある。
ただしベクターストアを使うより料金が高くなりやすいので注意⚠️
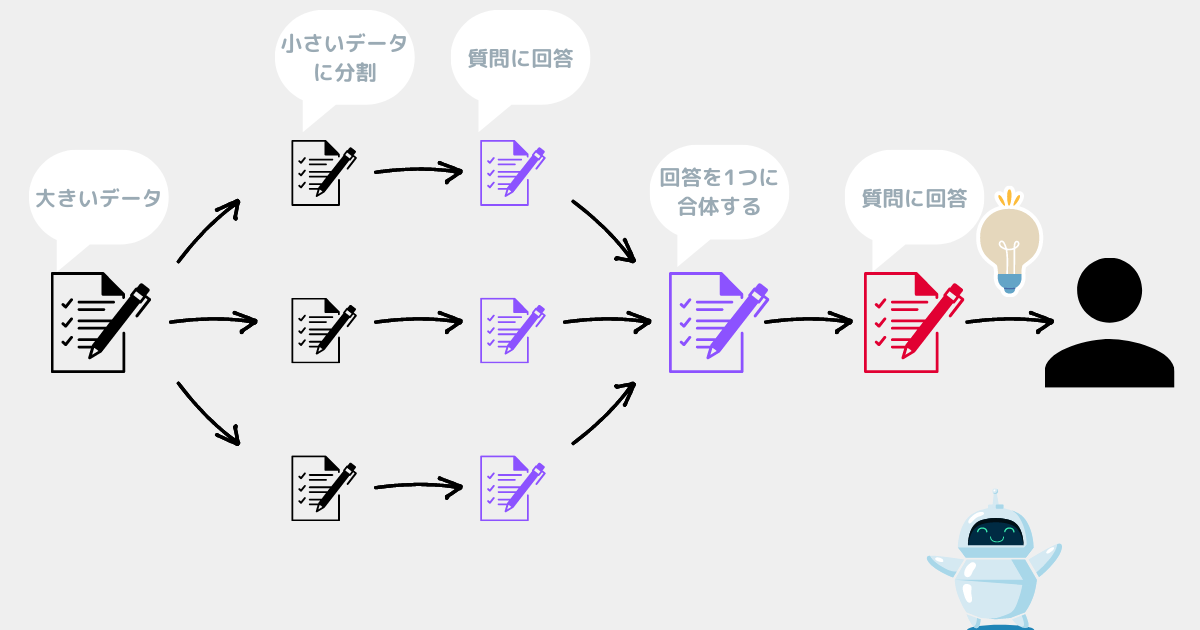
Map Reduce
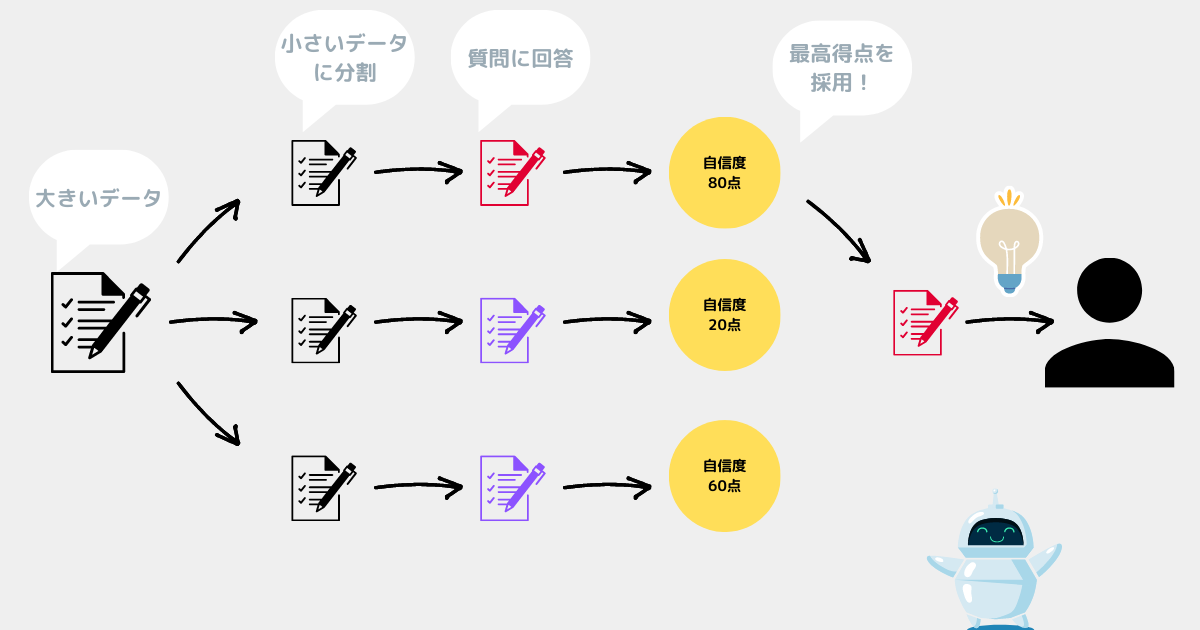
Map Rerank
Refine
上記手法の参考サイト
以下の動画の解説が分かりやすかった✅
※Python版だが考え方は同じ


こちらのサイトもわかりやすかった✅
※Python版

公式ドキュメントの解説はこちら。
※Python, TypeScript共通
※TypeScript版
参考サイト
公式ドキュメント
APIリファレンス
質問全体の流れ
Vector Stores「pinecone」を使った方法

Python版の説明だが少し参考になった

インデックスについて