はじめに
LangSmithが便利と聞いて使ってみた!
本当にめちゃくちゃ便利だったので基本的な使い方を画像付きでまとめる😊
この記事で伝えたいこと
✅LangSmithで何ができるか、どう便利かを理解する。
✅LangSmithの基本的な使い方を理解する。
結論
✅LangSmithは、LangChainの開発の補助にめっちゃ便利。
✅ログを残したり、モデルの評価したりできる。
✅環境変数を設定しておくだけで、自動でLangSmithと連携されて簡単に使える。
なぜ今まで使っていなかったのか後悔するくらい便利…!
LangSmithとは
✅LangChainの開発を助けてくれるツール。
※LangChainを使っていない場合でもLangSmithパッケージを使えば利用可能◎
詳細は公式ドキュメントを参照。
できること
代表的なできることを紹介する。
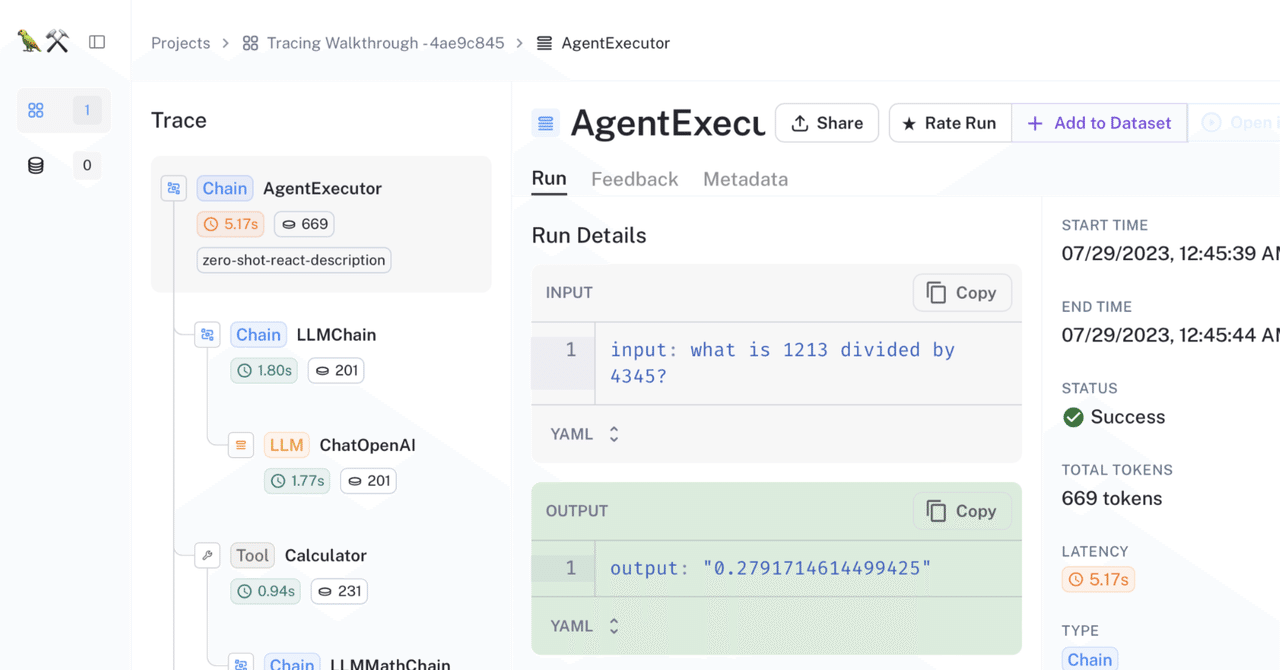
ログが残る
事前にLangChainのAPIキーを環境変数に設定しておくだけで、LLMを実行するとき自動で「LangSmithのクラウドのデータベース」にログが蓄積される!
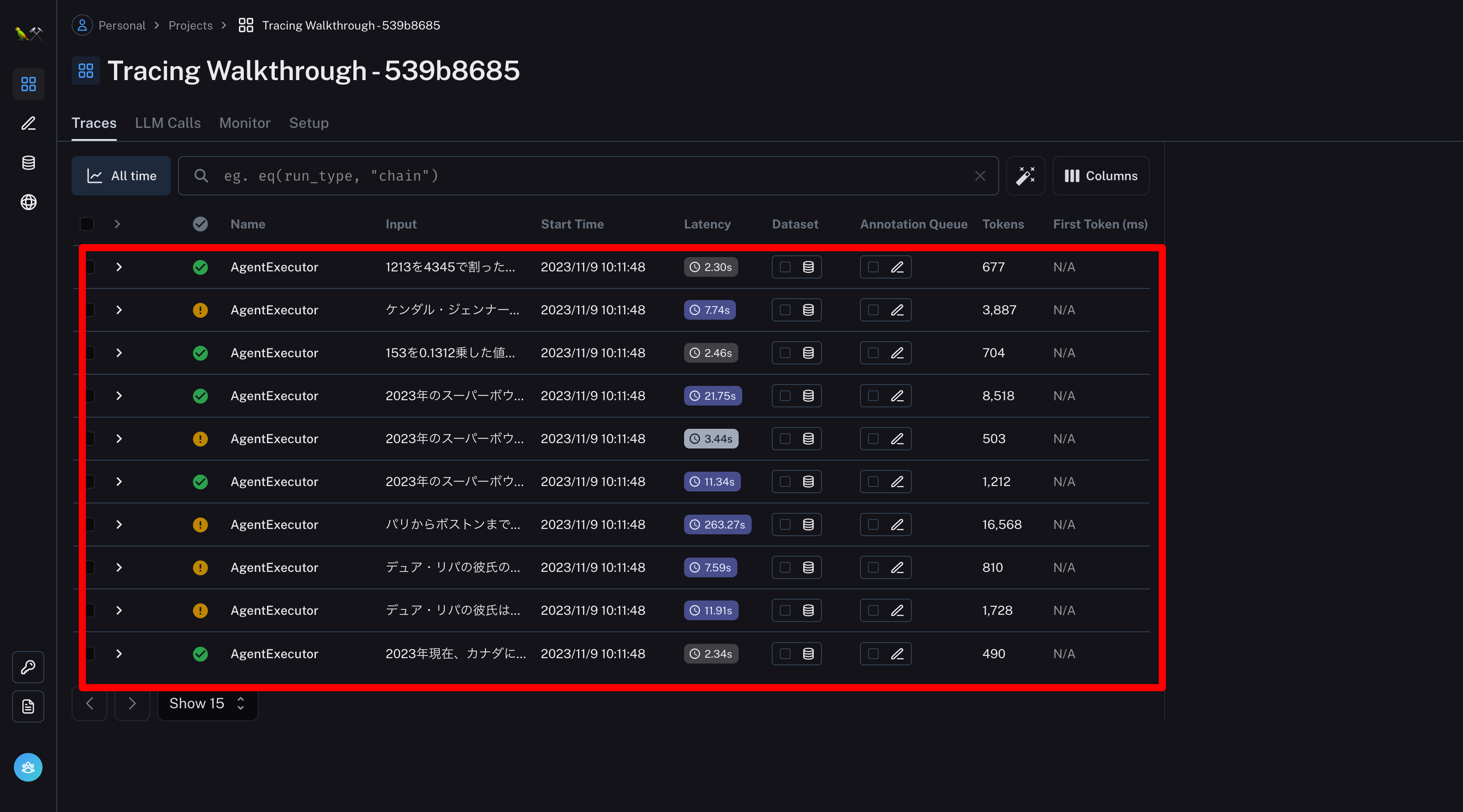
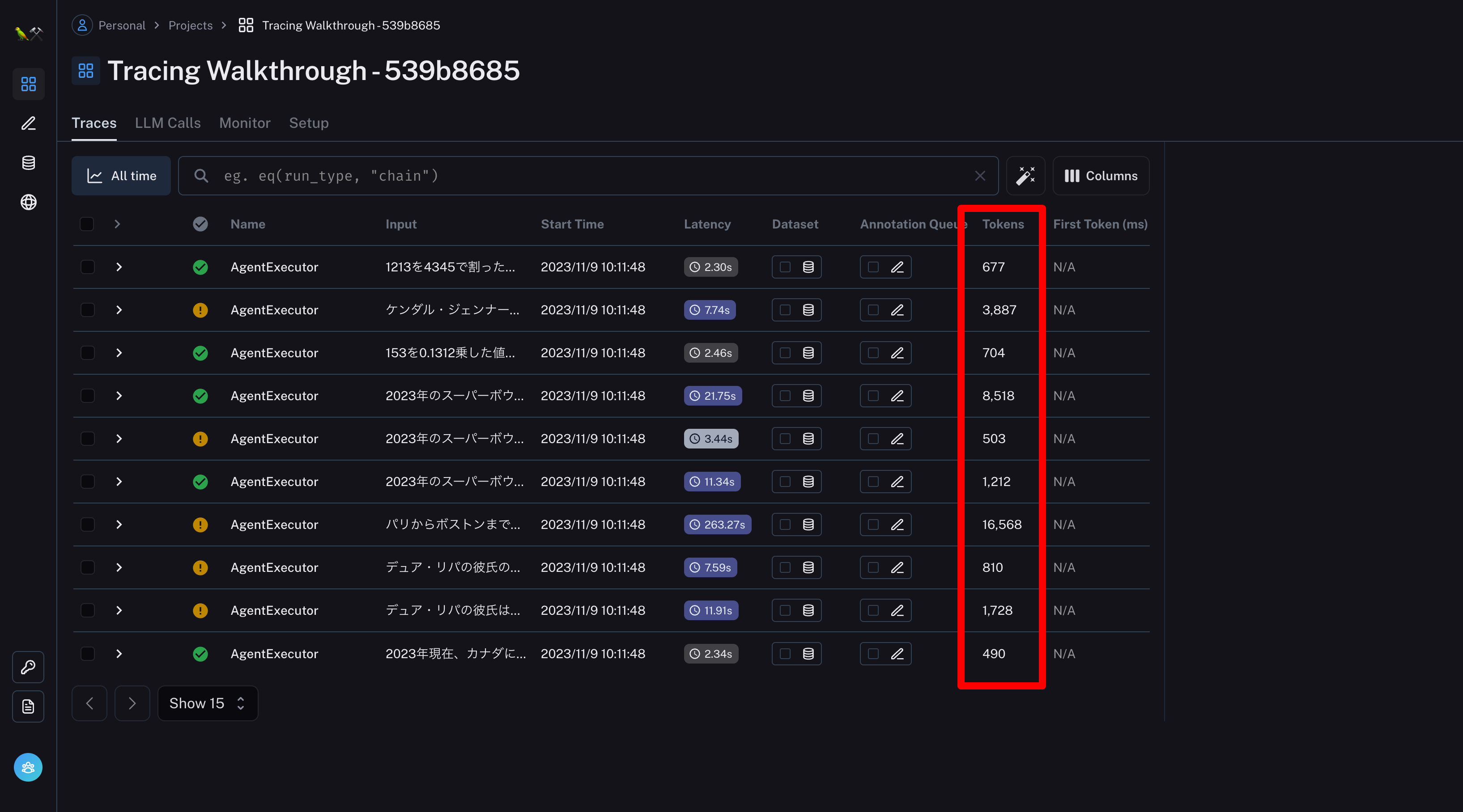
消費トークン数を計測
ログと一緒に消費トークン数も蓄積される!
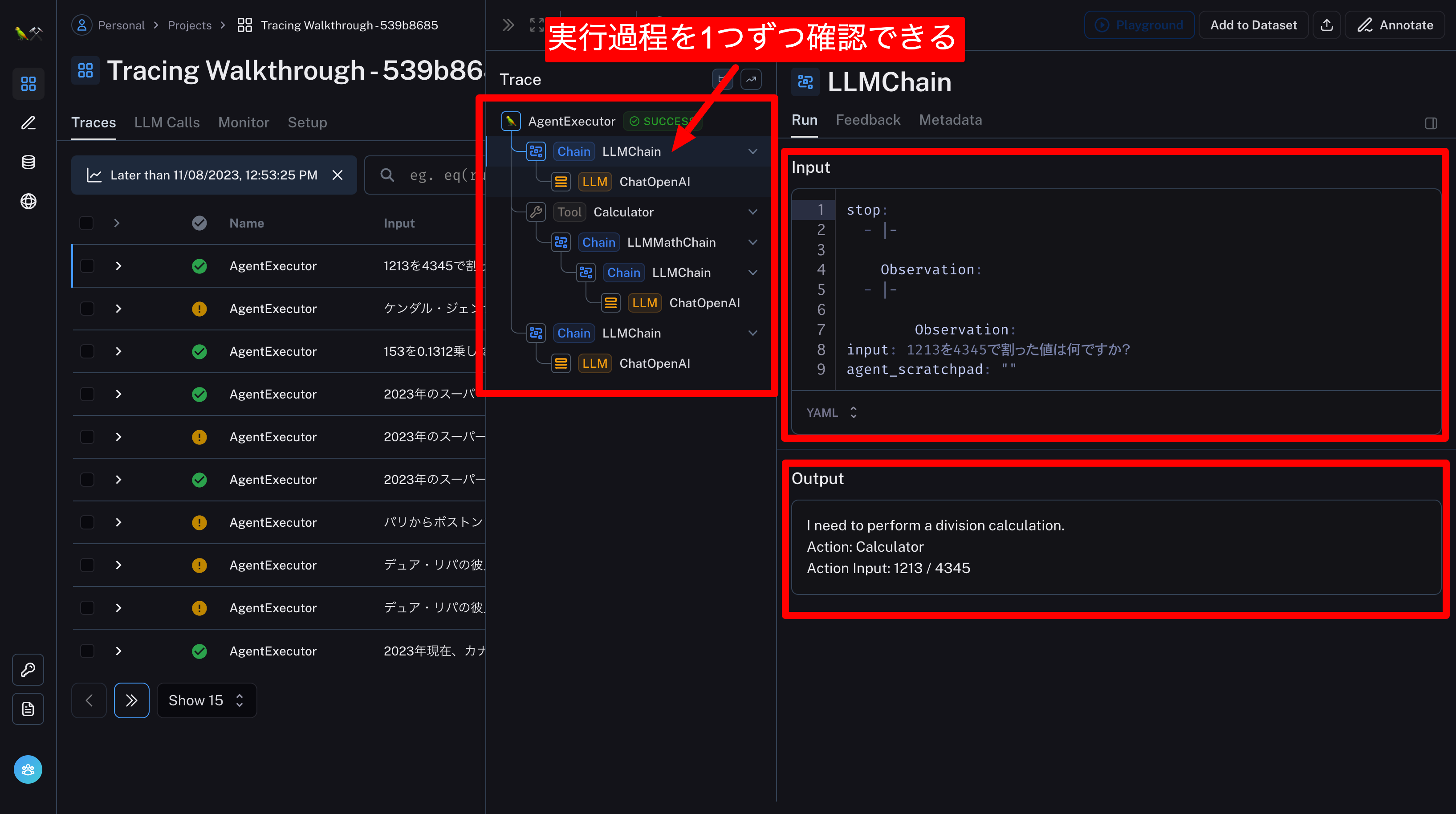
チェーンの中身を確認する
複雑なチェーンでもどこで精度が悪くなっているか確認できる!
実行結果を自動で評価してもらえる
サンプルとなる回答を用意すれば、実行結果を自動で評価してもらえる!
役立ちそうな場面
- ログを残したいとき
- カスタマイズしたモデルの評価をするとき
- カスタマイズしたモデルの精度を向上させたいとき
基本的な使い方
使用技術
今回使用するものは以下のとおり。
言語
- Python(もしくはTypeScript)
ライブラリ
- LangChain
- LangSmith
- tiktoken
- OpenAI(OpenAIのモデルを使わない場合は不要)
- python-dotenv
API
- LangSmithのAPI
- OpenAIのAPI(OpenAIのモデルを使わない場合は不要)
LangSmithの登録
✅以下のサイトからLangSmithに登録する。
(利用可能になるまでしばらく待つ必要がある)
LangSmithのAPIキーを生成
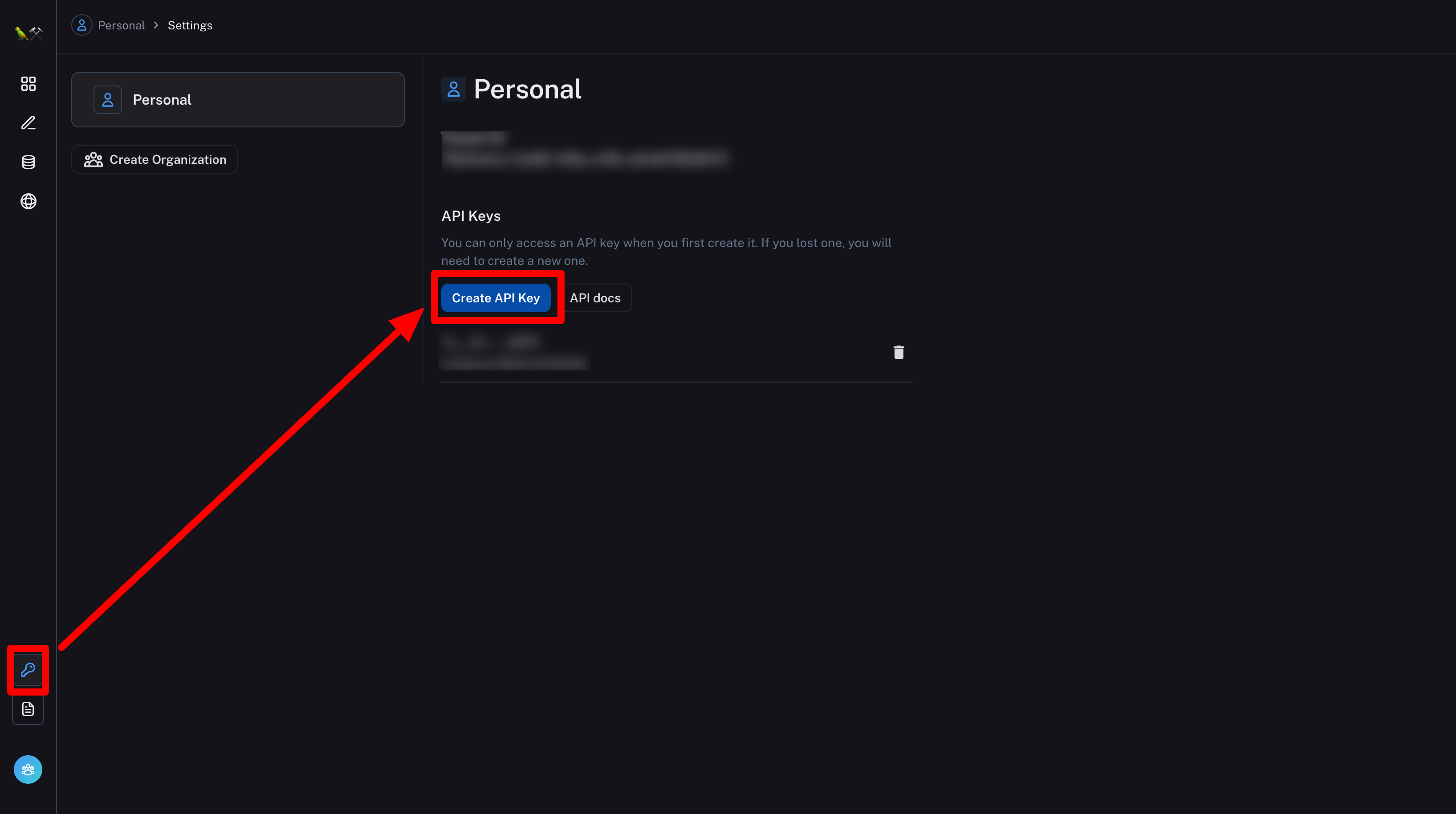
OpenAIのAPIキーを生成
✅以下のサイトからAPIキーを発行する。
※OpenAIの以外のLLMを使う場合は、適宜他サービスのAPIキーを用意する。
フォルダを作成
✅任意の名前の新規フォルダを作成する。
今回は「env_LangChainTest」というフォルダ名にした。

各種ライブラリのインストール
✅Pythonのライブラリをインストールしていく。
(Python、pipはインストール済みの前提。)
プロジェクトのディレクトリに移動
cd env_LangChainTestlangchainをインストール
pip install langchainlangsmithをインストール
pip install langsmithopenaiをインストール
pip install openaitiktokenをインストール
pip install tiktokenpython-dotenvをインストール
pip install python-dotenv環境変数の設定
✅LangSmithを使うために必要な環境変数を.envに記述する。
プロジェクトディレクトリの直下に.envを作成する。
.env
LANGCHAIN_TRACING_V2 = true
LANGCHAIN_ENDPOINT = "https://api.smith.langchain.com"
LANGCHAIN_API_KEY = "your-api-key" # LangSmithのAPIキーを入力してください
LANGCHAIN_PROJECT = "sample-project" # 任意のプロジェクト名を入力してください
OPENAI_API_KEY = "your-api-key" # OpenAIのAPIキーを入力してください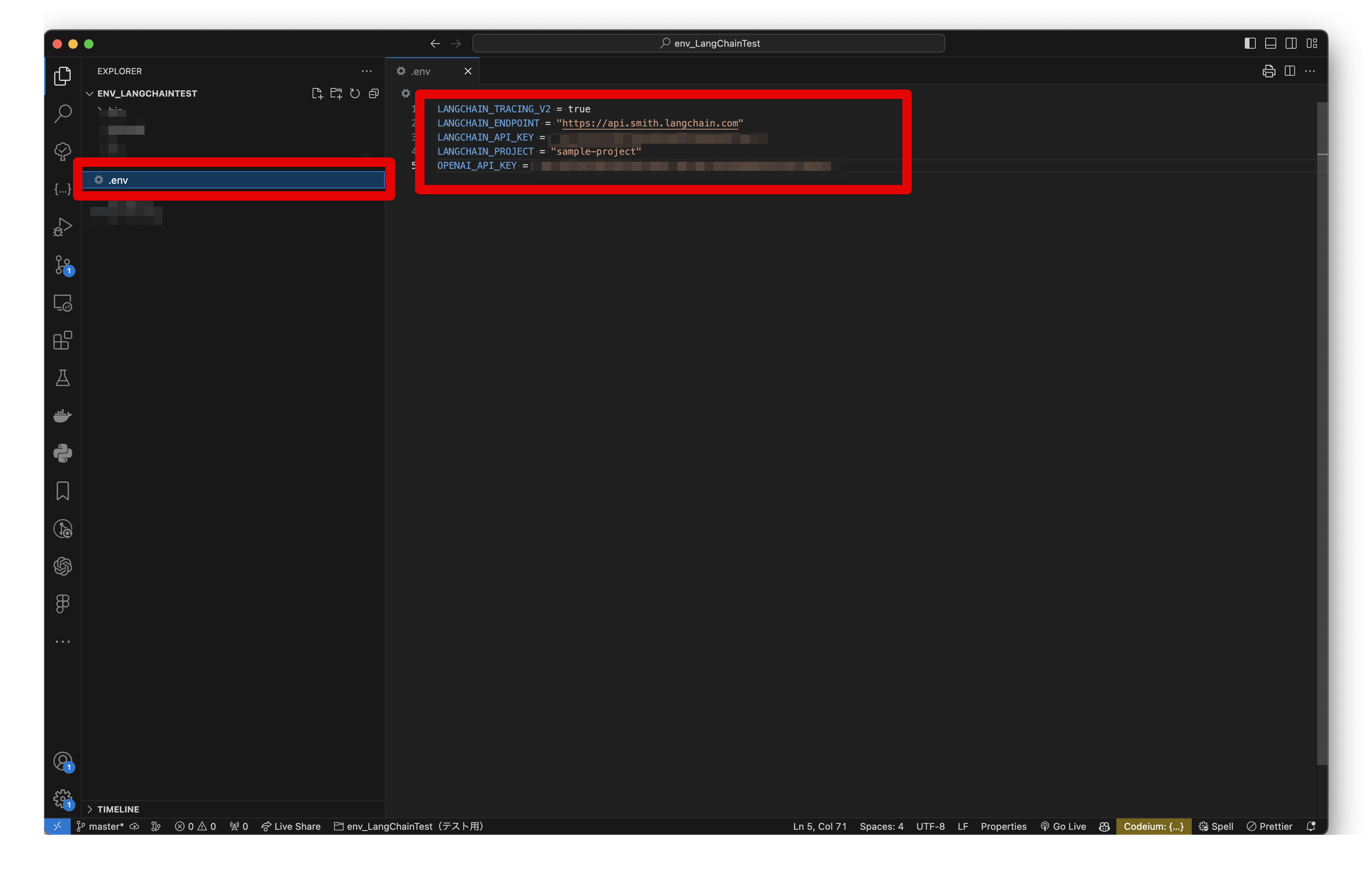
サンプルコードの作成
✅最小限のサンプルコードを作成する。
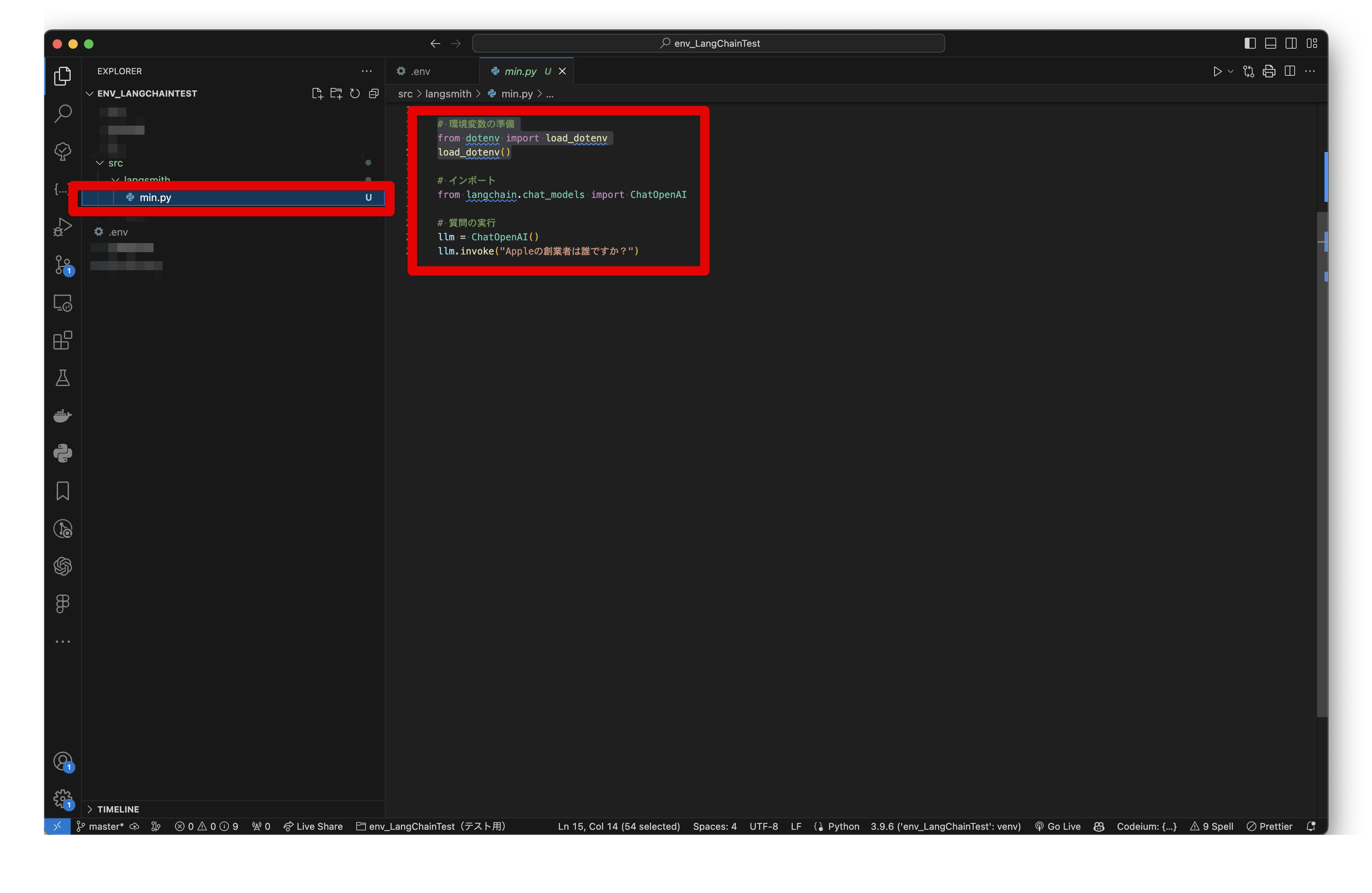
src/langsmith/min.py(ファイル名、保存場所は任意)
# 環境変数の準備
from dotenv import load_dotenv
load_dotenv()
# インポート
from langchain.chat_models import ChatOpenAI
# ✅質問の実行
llm = ChatOpenAI()
llm.invoke("Appleの創業者は誰ですか?")✅質問の実行
# ✅質問の実行
llm = ChatOpenAI()
llm.invoke("Appleの創業者は誰ですか?")- 「Appleの創業者は誰ですか?」という質問をしているだけ。
- LangSmithに関する処理は一切ないが、ログを自動でLangSmithに出力してくれる✨
LANGCHAIN_TRACING_V2がtrueに設定されている場合、質問のログを自動でLangSmithに出力してくれる✨サンプルコードを実行する
以下のコマンドを実行するだけ。
※パス、ファイル名は環境に応じて変える。
python src/langsmith/min.py実行結果を確認する
✅LangSmithの管理画面で実行結果を確認できる!
プロジェクトの画面へ移動する
まずLangSmithのページを開く。
Projectsを選択。
「sample-project」を選択。
※プロジェクト名は環境変数LANGCHAIN_PROJECTで指定したもの。
実行の過程を確認する
確認したいログを選択する。
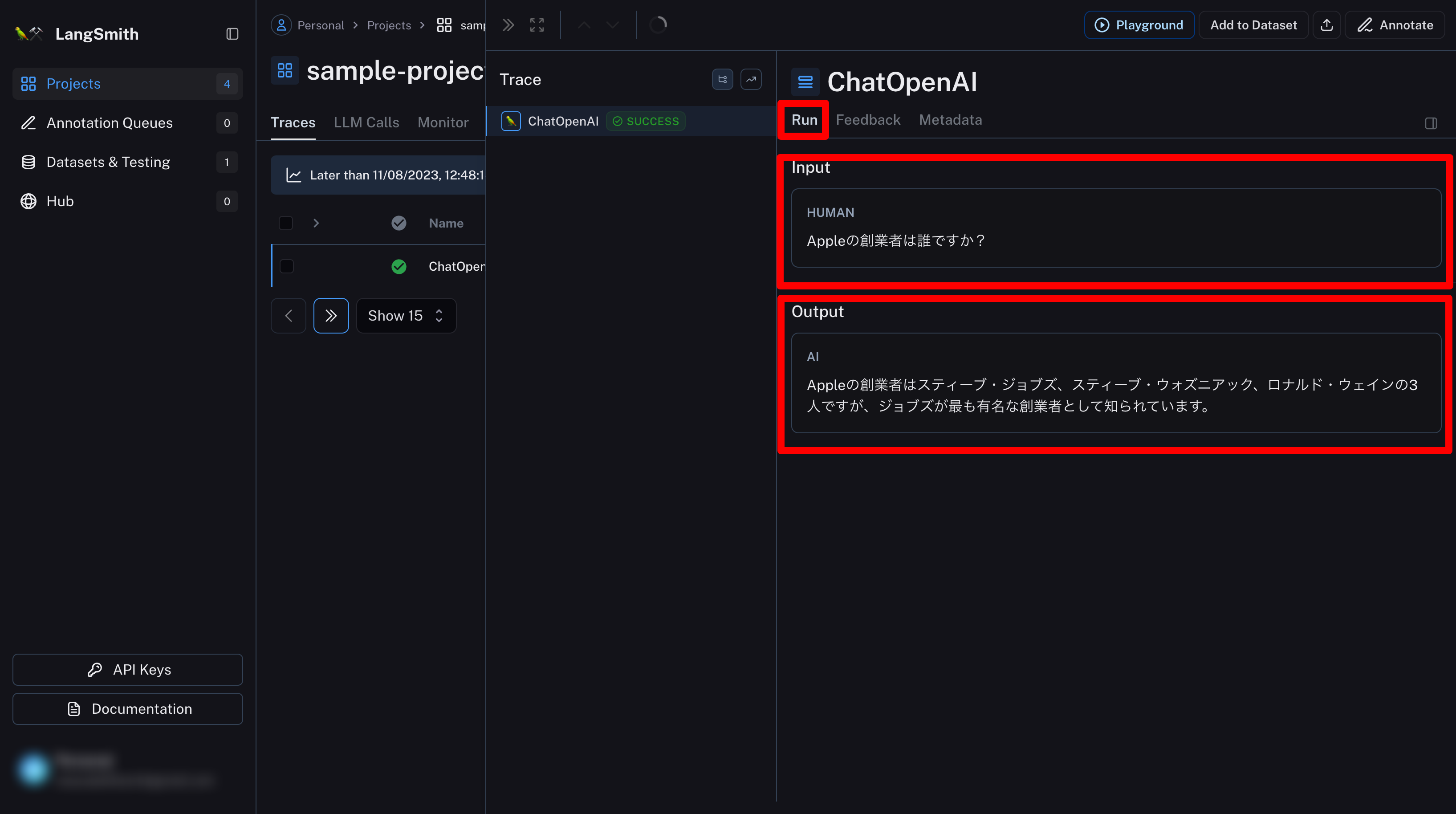
Runタブで入力、出力が確認できる。
※今回はシンプルな例だったので細かい実行過程が存在しない。
例:Agent(LangChainの機能)を使ったプログラミングを実行した場合
答えが出るまでの詳しい過程を1つずつ確認できる。
その他の便利な機能
実行結果の確認以外にも管理画面でさまざまなことができる😊
代表的な機能は以下のとおり。
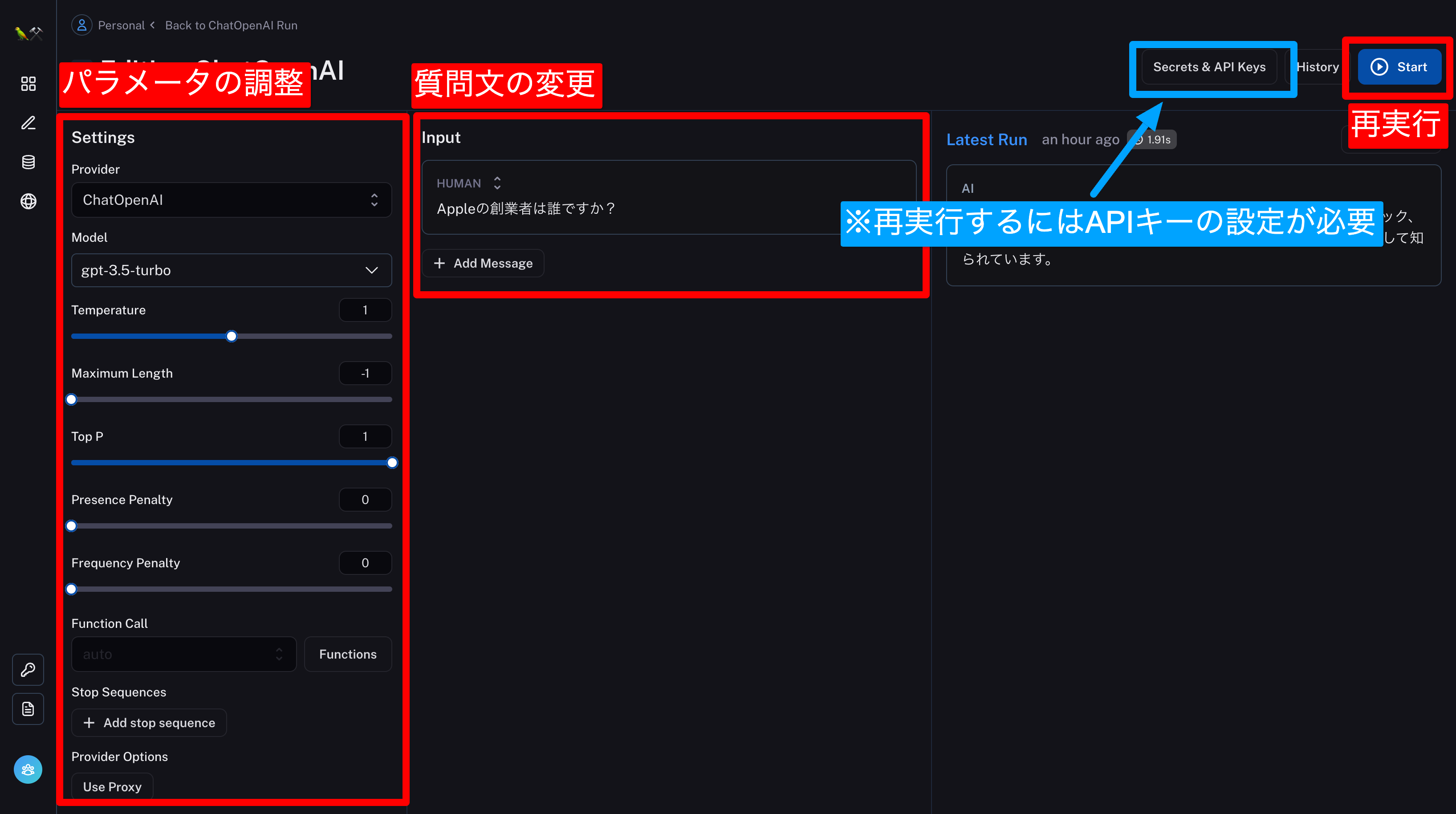
- その場でLLMのパラメータを変更して再実行する💡どのパラメータがいいか?を微調整するのに便利!
- テスト実行と自動評価💡カスタマイズしたモデルの精度を評価するのに便利!
その場でLLMのパラメータを変更して再実行する
プロジェクト画面で、確認したいログを選択する。
Playgroundを選択
パラメータや質問文を変更して、再実行。
回答が合っているか自動で評価してもらう
- まずサンプルとなる質問と回答を用意する。
- 評価用のプログラムを作成する。
- 評価用のプログラムを実行後、管理画面で評価結果を確認する。
✅まずはサンプルとなる質問と回答を用意する。
サンプルの用意の仕方は主に2種類ある。
- 管理画面で登録(今回はこっち!)
- Pythonプログラムで登録(公式ドキュメントを参照)
プロジェクト画面で、サンプルとして登録したいログを選択する。
Add to Datasetを選択
データセットの名前を入力する
(今回はデータセット名をsample-datasetとする)
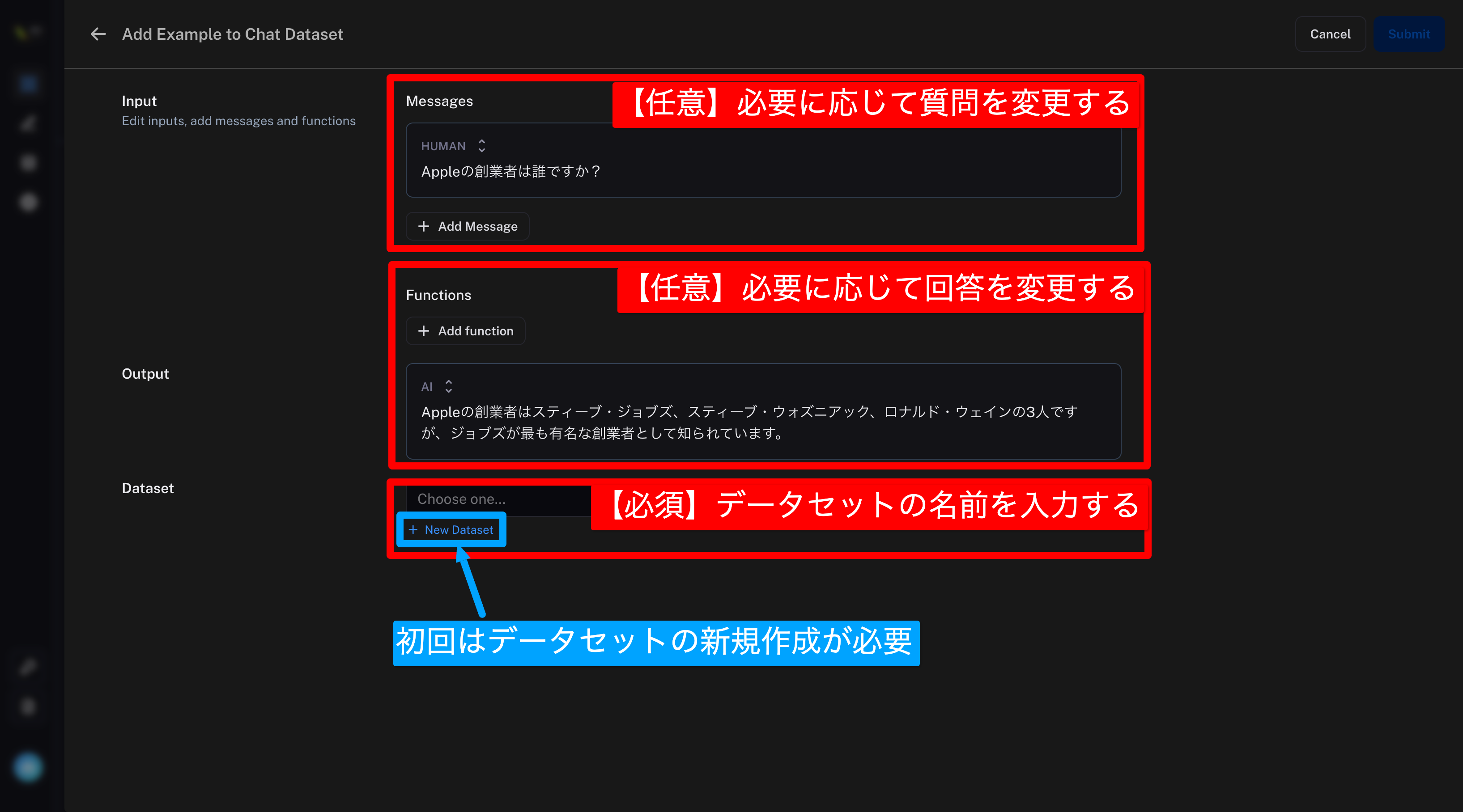
Submitを選択
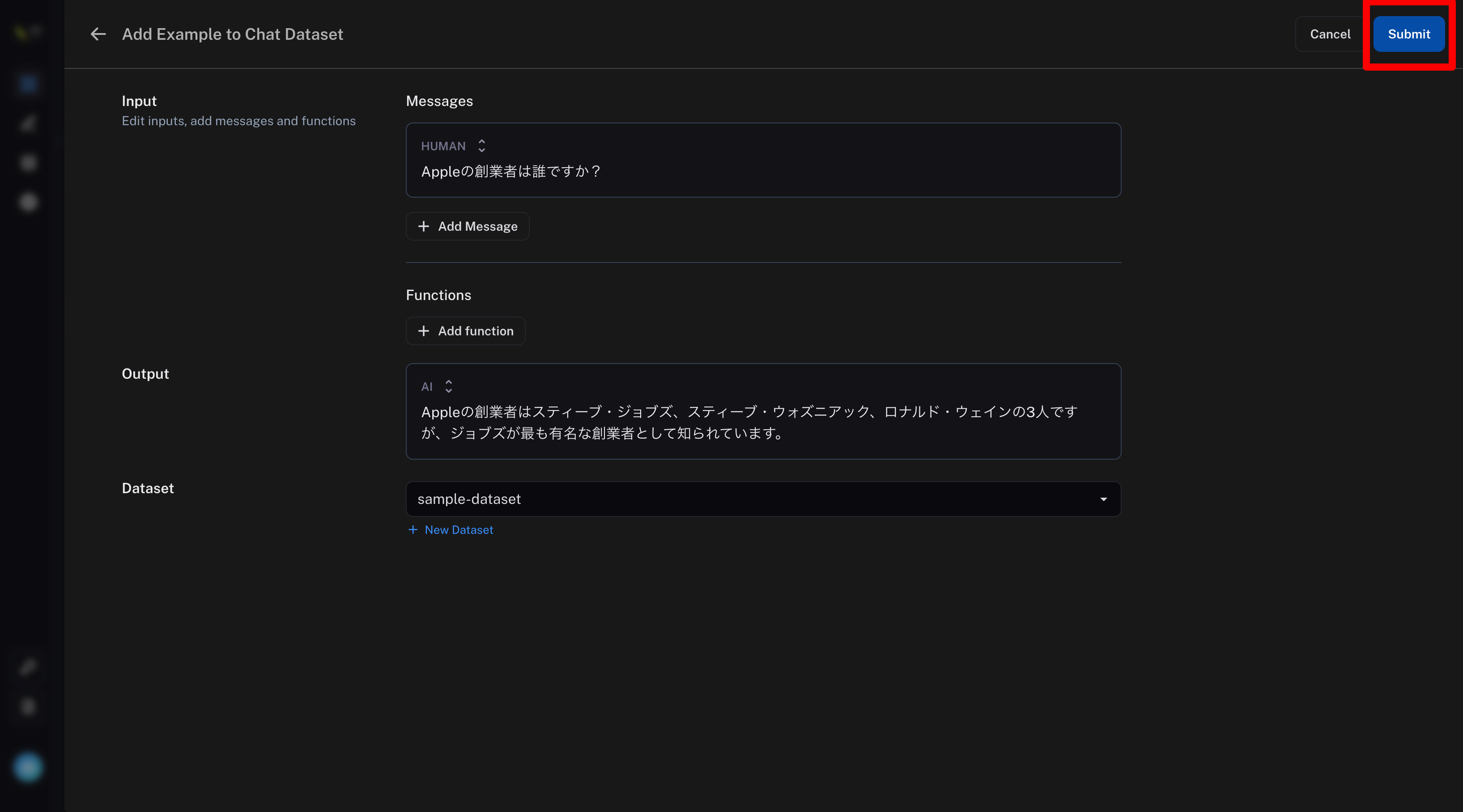
これでデータセット(サンプル)が登録できた😊
サイドバーのDatasets & Testingを選択すると登録したデータセットを確認できる

✅評価用のプログラムを作成する。
src/langsmith/eval.py(ファイル名、保存場所は任意)
# 環境変数の準備
from dotenv import load_dotenv
load_dotenv()
# インポート
from langchain.chat_models import ChatOpenAI
from langchain.smith import run_on_dataset, RunEvalConfig
from langsmith import Client
# データセット名
dataset_name = "sample-dataset"
# LangSmithのクライアント
client = Client()
# LLMを準備
llm = ChatOpenAI(temperature=0)
# 評価の設定
eval_config = RunEvalConfig(
evaluators=[
"qa"
]
)
# 評価の実行
run_on_dataset(
dataset_name=dataset_name,
llm_or_chain_factory=llm, # LLMのインスタンス
evaluation=eval_config, # 評価の設定
client=client, # LangSmithのクライアント
verbose=True, # 実行ログを表示
project_name="sample-test-1", # 任意のプロジェクト名
)プログラムを実行する
※パス、ファイル名は環境に応じて変える。
python src/langsmith/eval.py✅管理画面で評価結果を確認する。
サイドバーのDatasets & Testing
→ Testsタブ
→ プロジェクト名(今回はsample-test-1)を選択
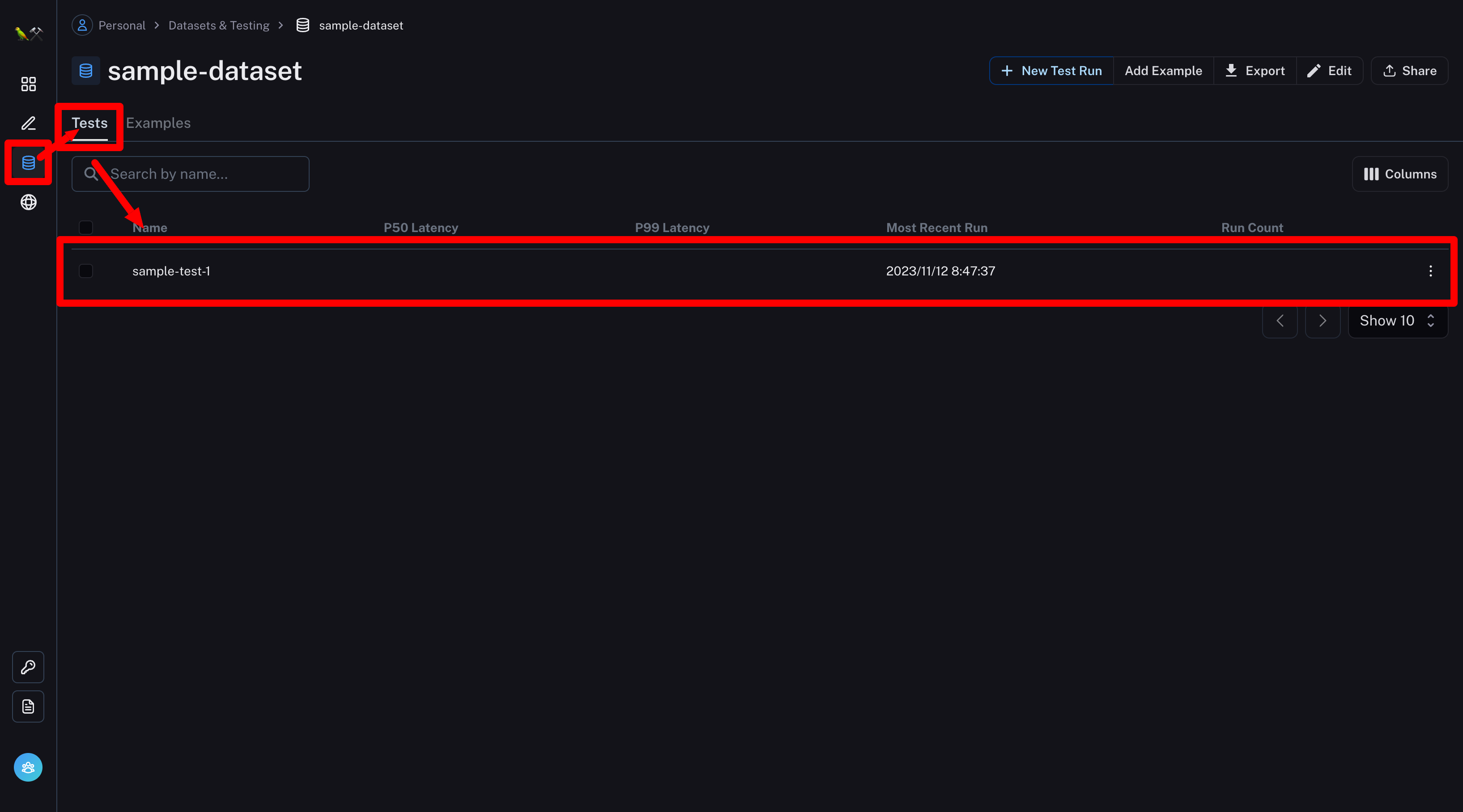
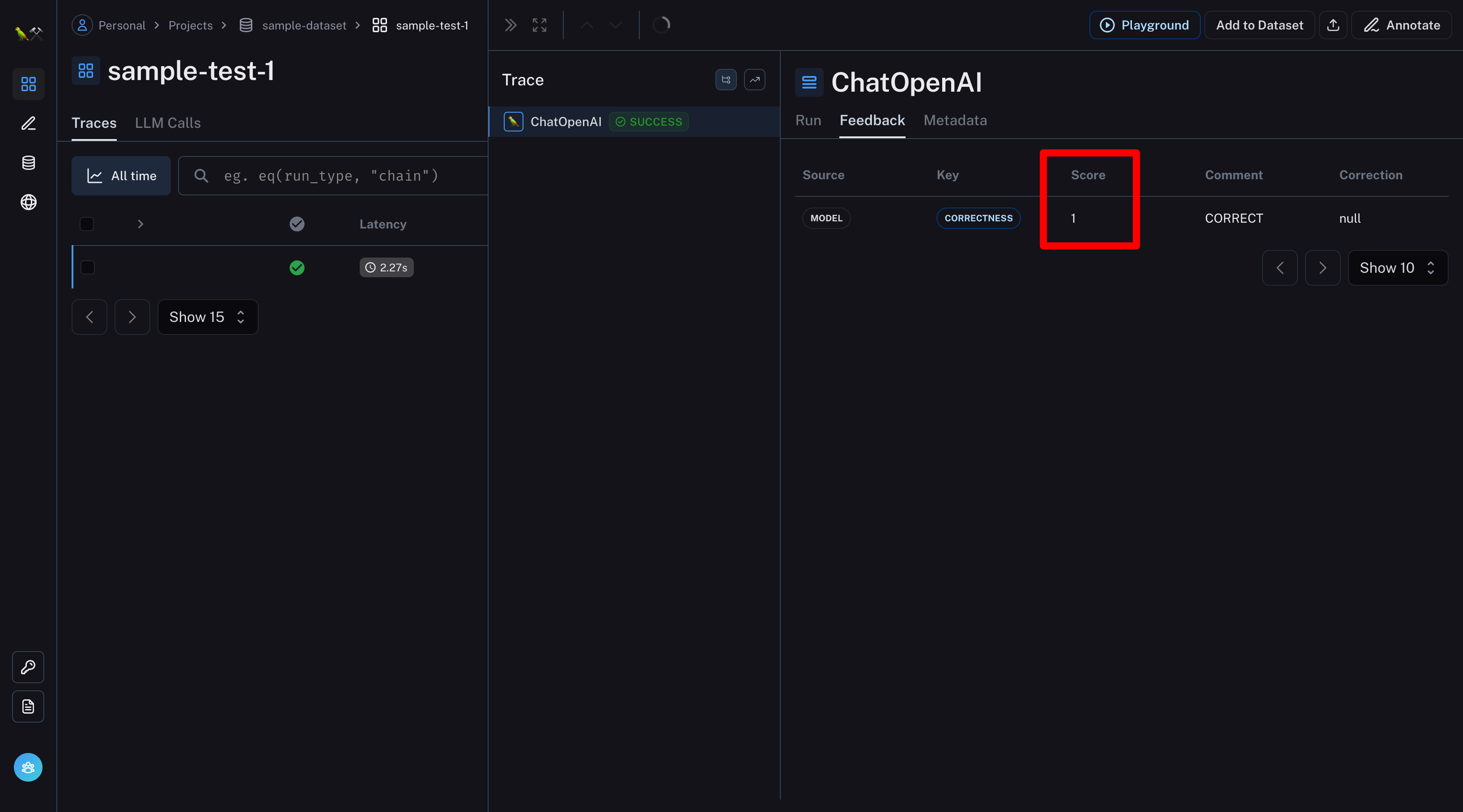
評価ログを選択
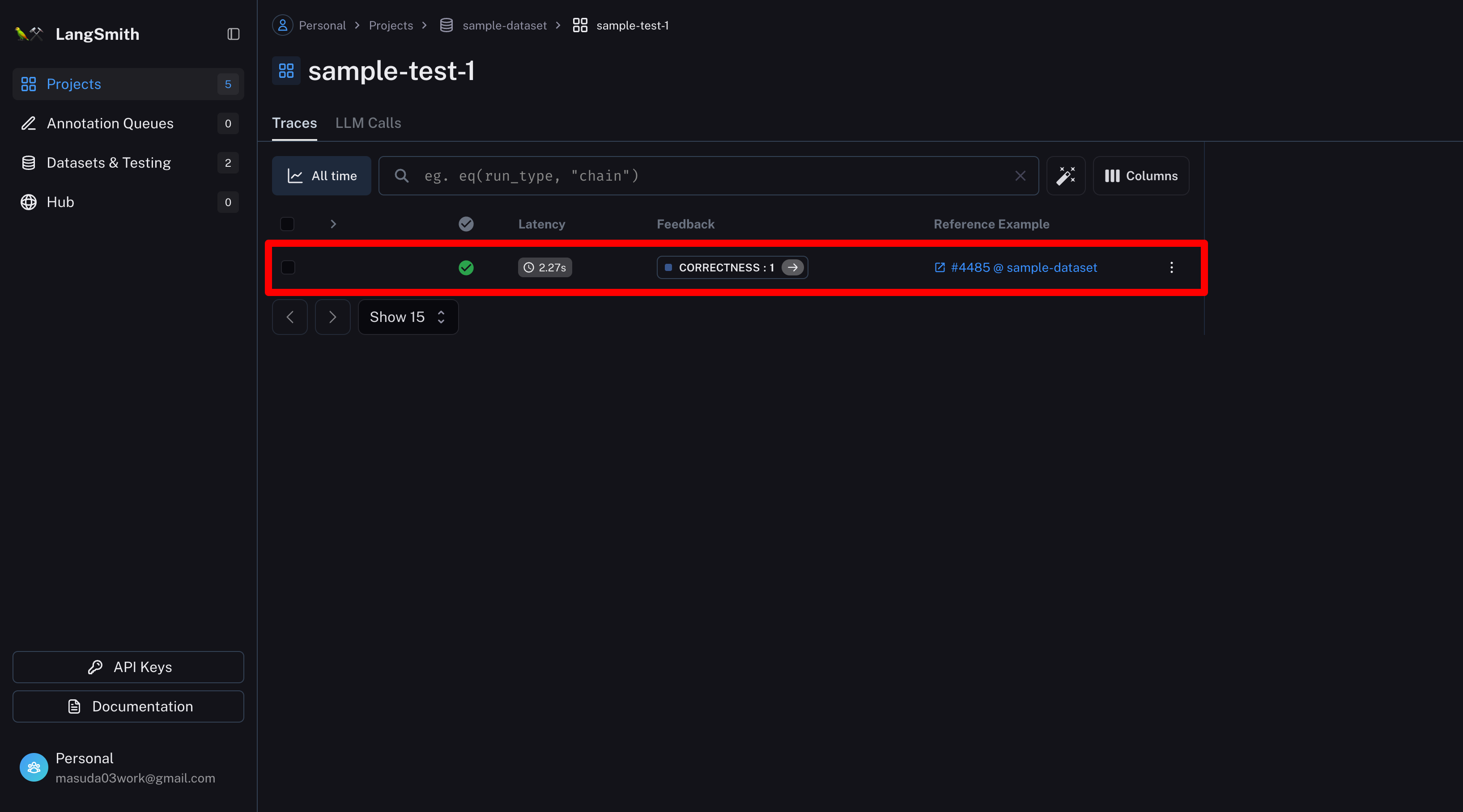
事前に用意したサンプルと、実行結果を確認できる
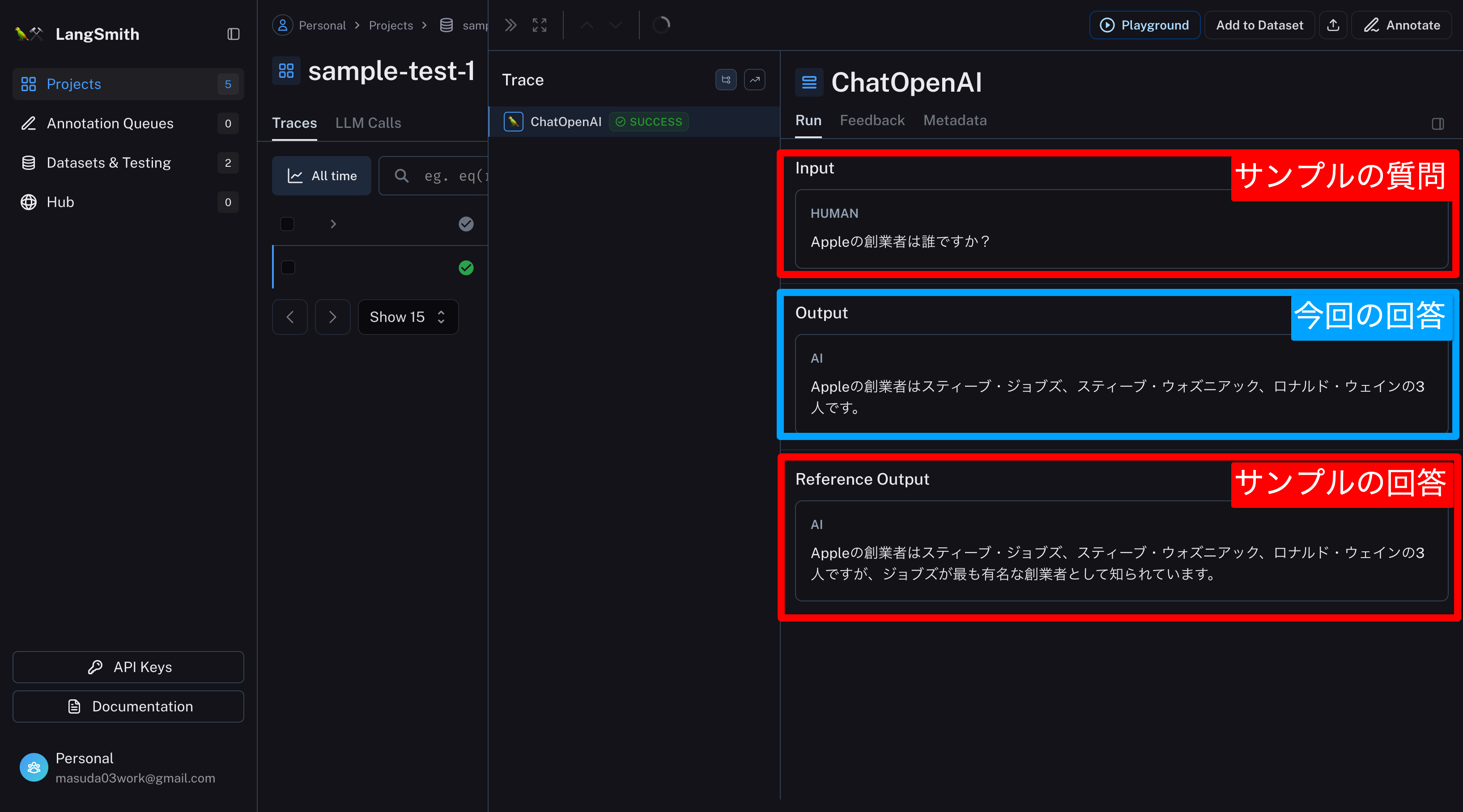
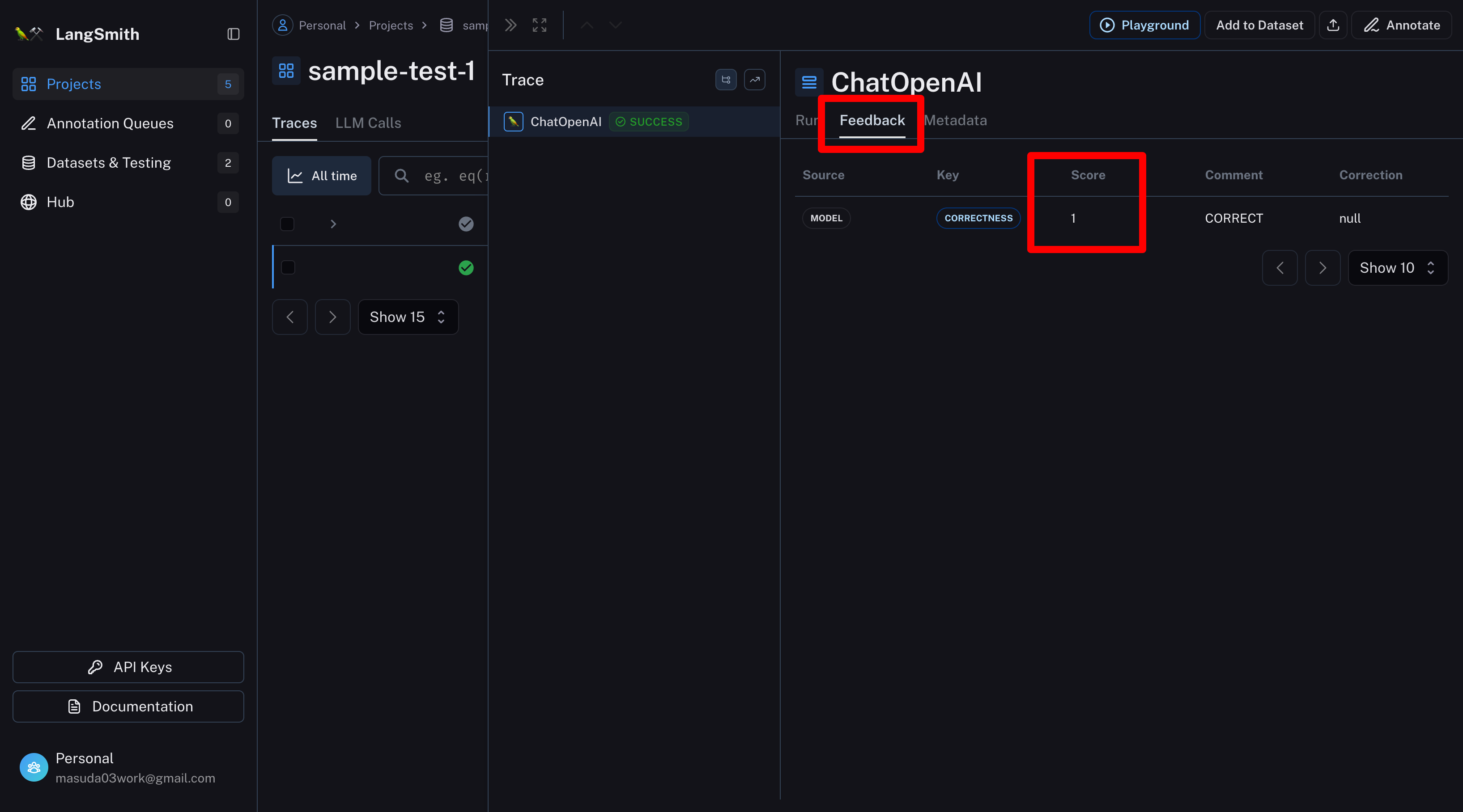
Feedbackタブで評価結果(Score)を確認できる
※Scoreは1が最高点。
よくある質問
公式ドキュメントでよくある質問がまとめられている。

参考サイト
公式ドキュメント
公式のLangSmith紹介記事
分かりやすい解説サイト