

(2023/11/7更新)
概要
プログラミング言語を問わず、ChatGPTのAPIで必要な知識を備忘録として残す。
主に公式ドキュメントから重要そうな部分をピックアップしている。
前提知識
価格
- 有料。従量課金制。
- 使用したトークン数に応じて課金される。(*1)
- 利用料金は上限額を設定できる。
- モデルによって価格が異なる。
(*1)トークン数とは
✅トークン数とは英語だと単語数、日本語だと文字数のこと。
- 日本語と英語で違いがある
- ひらがなは1文字で1トークンだが、漢字は1文字で2〜3トークン消費する。
✅トークン数の計算
一回のやりとりで以下のトークンが消費される。
- (質問トークン)+(回答トークン)=(合計トークン)
ちなみに料金目安は以下のとおり
(gpt-3.5-turbo-1106モデル使用。2023/11/7時点。)
| 使用トークン数 | 料金(ドル) | 料金(円) |
|---|---|---|
| 1,000 | 0.001 | 0.15 |
| 10,000 | 0.01 | 1.5 |
| 100,000 | 0.1 | 15 |
| 500,000 | 0.5 | 75 |
| 1,000,000 | 1.0 | 150 |
データの取扱い
- APIを使うと学習データとして使用されない。
- ただし30日間OpneAIでデータが保管される。
できること
チャット
チャットベースの言語モデルを使用できる。
例:チャットボットが作れる。
Vision
チャットの進化版。質問に画像が使える。
例:画像を使った質問が可能な強化版チャットボットが作れる。
テキスト補完
テキストの生成や修正ができる。
例:文章の続きを生成できる。
Embeddings
テキスト同士の距離の近さを数値化する。
例:似た文章を探すことができる。
音声→テキスト
音声をテキストに変換できる。
例:文字起こしができる。
テキスト→音声
テキストを音声に変換できる。
例:台本を読み上げてもらうことができる。
画像生成
画像の生成や修正ができる。
例:テキストから新しい画像を生成する。
トレーニング
必要に応じて言語モデルを独自にカスタマイズできる。
例:専門的なチャットボットが作れる。
ライブラリ
APIが簡単に使えるように公式や有志の方がライブラリを提供している✅
本格的な開発をする場合は要チェック!
公式で紹介されているライブリラリ
言語ごとにライブラリが用意されている。詳細は以下を参照。
おすすめのライブリラリ
LangChainがおすすめ✅
簡単なコードで複雑なタスクを実行できるため効率的に開発できる😊
モデル
APIでは用途に応じたモデルを選択して使う✅
| モデル | 説明 |
|---|---|
| GPT-4 | 自然言語、コードを生成できるモデル(GPT-3.5の改良版) |
| GPT-3.5 | 自然言語、コードを生成できるモデル(GPT-3の改良版) |
| DALL·E | 画像生成、修正ができるモデル |
| TTS | テキストを音声テキストに変換するモデル |
| Whisper | 音声をテキストに変換できるモデル |
| Embeddings | 2つのテキストの距離の近さを数字で表現するモデル |
| Moderation | テキストがOpenAIのポリシーに準拠しているかを検出できるモデル |
| GPT-3 | 自然言語を生成できるモデル |
(2023/11/7時点)
GPT-3、GPT-3.5、GTP-4はどれがおすすめ?
- 精度を優先する場合は「GPT-4」がおすすめ!
- 価格を優先する場合は「GPT-3.5」がおすすめ!
APIを使う前に必要なこと
✅ChatGPTのアカウントを取得
普通にアカウントを取得するだけ。
ChatGPTを使ったことある人なら取得済み。
✅クレジットカードの登録
OpenAIのページ(https://platform.openai.com/account/billing/overview)で登録できる。
最初の3ヶ月は登録不要だが、無料枠($5)を超えて使う場合は登録が必要になる。
✅APIキーを発行
OpenAIのページ(https://platform.openai.com/account/api-keys)から発行できる。
1度しか表示されないので必ずメモしておく!
リクエスト
APIを使うときのリクエストについて解説する。
リクエストの概要
- 質問情報をリクエストとして送信する。💡「質問」「どのモデルを使うか」「トークン数の制限」など
- 指定できるパラメータはモデルによって異なる。
- どのモデルでも必ず「APIキー」「エンドポイント」は必要。
手軽に試す方法
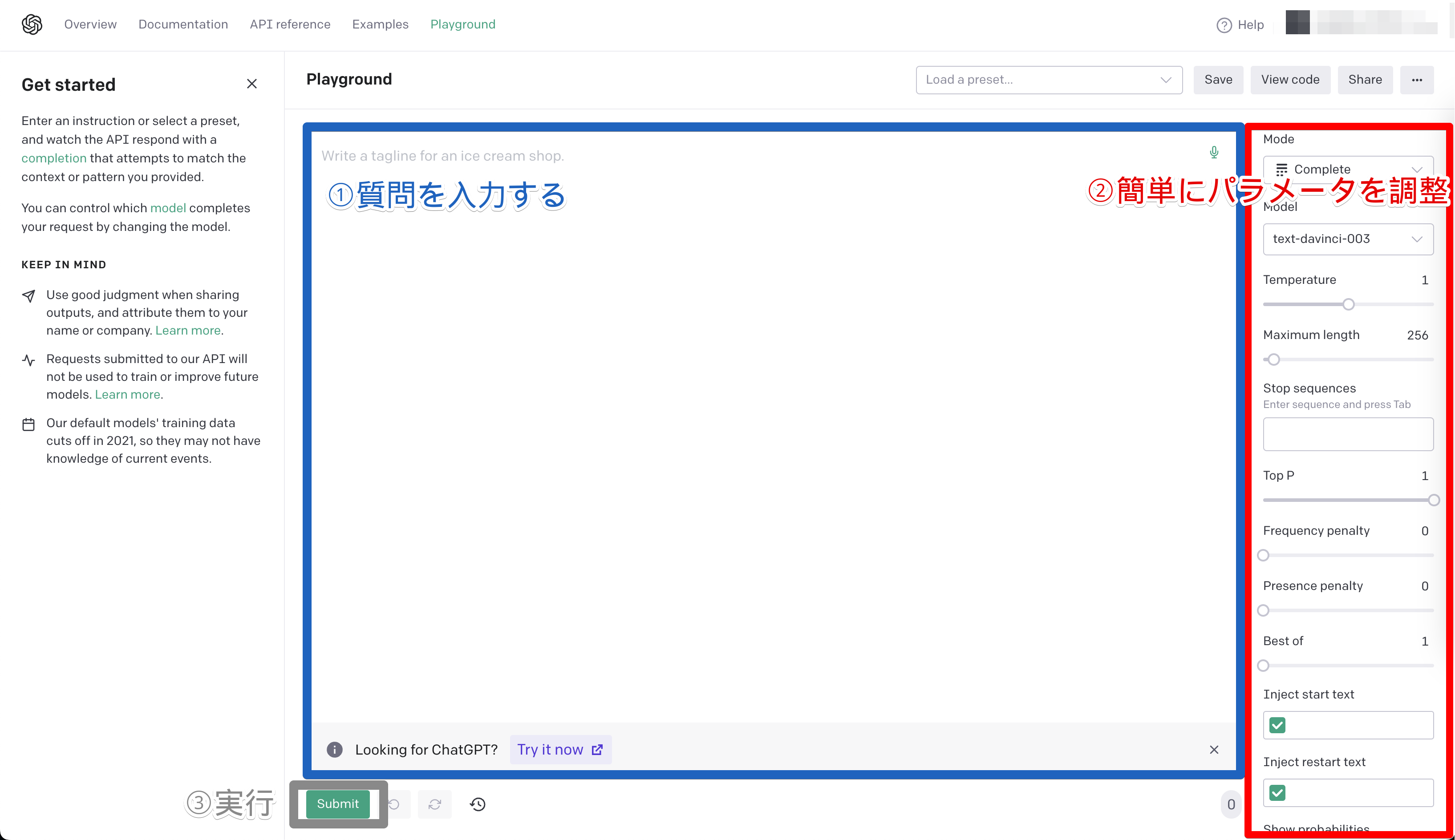
早見表
指定できるパラメータはモデルによって異なる。
ここでは2種類のモデル「Completions」「Chat」のパラメータを簡単に紹介する。
【①従来のモデル】Completionsのパラメータ
モデル「text-davinci-003」などで使うパラメータ。
エンドポイントはhttps://api.openai.com/v1/completionsを指定する。
| パラメーター名 | データ型 | 必須/任意 | デフォルト値 | 説明 |
|---|---|---|---|---|
| model | 文字列 | 必須 | --- | 使用するモデル名。(*1) |
| prompt | 文字列 | 任意 | <|endoftext|> | 質問の文章。 |
| suffix | 文字列 | 任意 | null | 回答の後ろに付ける文字列。 |
| max_tokens | 整数 | 任意 | 4096 - 入力トークン数 | 回答文章のトークンの最大数。 |
| temperature | 数値 | 任意 | 1(ブラウザ上のChatGPTは0.7) | 回答のランダム度合いを0〜2の間で指定。値が高いほど多様な単語が選ばれる。 |
| top_p | 数値 | 任意 | 1(ブラウザ上のChatGPTは0.9~0.95) | 回答の正確性を0〜1の間で指定。値が小さいほど、正確になる。temperatureパラメーターとどちらかのみ指定可能。 |
| n | 整数 | 任意 | 1 | 回答の数。 |
| stream | 論理型 | 任意 | false | true:逐次レスポンスを受け取る。(前回のレスポンスとの差分だけ受け取る) false:すべて回答が終わってからレスポンスを受け取る。(すべてのレスポンスを受け取る) |
| logprobs | 数値 | 任意 | null | レスポンスで生成されたトークンの対数確率をいくつ取得するか。 |
| echo | 論理型 | 任意 | false | 回答だけでなく質問文もレスポンスに含める。 |
| stop | 文字列 | 配列 | 任意 | null | 回答を停止する単語を最大4つまで指定。(特定の単語が出たときに回答を強制停止できる) |
| presence_penalty | 数値 | 任意 | 0 | 同じ単語を使った場合のペナルティ(-2.0〜2.0)。値が高いほどペナルティが重く同じ単語は使わない。 |
| frequency_penalty | 数値 | 任意 | 0 | presence_penaltyとほぼ同じ。こちらは同じ単語を繰り返すほどペナルティが重くなる(2回程度の繰り返しはOKだが、何回も繰り返されるのが嫌なときに使えそう)。 |
| best_of | 数値 | 任意 | 1 | 回答を生成する数。生成した中からn個の回答を返す。 ※best_of > n であること。 |
| logit_bias | 配列 | 任意 | null | 特定の単語の出現頻度(-100〜100)を指定する。 -100:ほぼ一切出現しない。 -1:少し出現しづらい。 1:少し出現しやすい。 100:ほぼ必ず出現する。 |
| user | 文字列 | 任意 | null | エンドユーザーを一意に識別するための文字列。悪用の防止に使える。 |
(*1)指定できるモデル一覧
公式サイトにモデル一覧が記載されている。
/v1/completionsの行を参照。
(2023年11月7日現在の公式サイト)
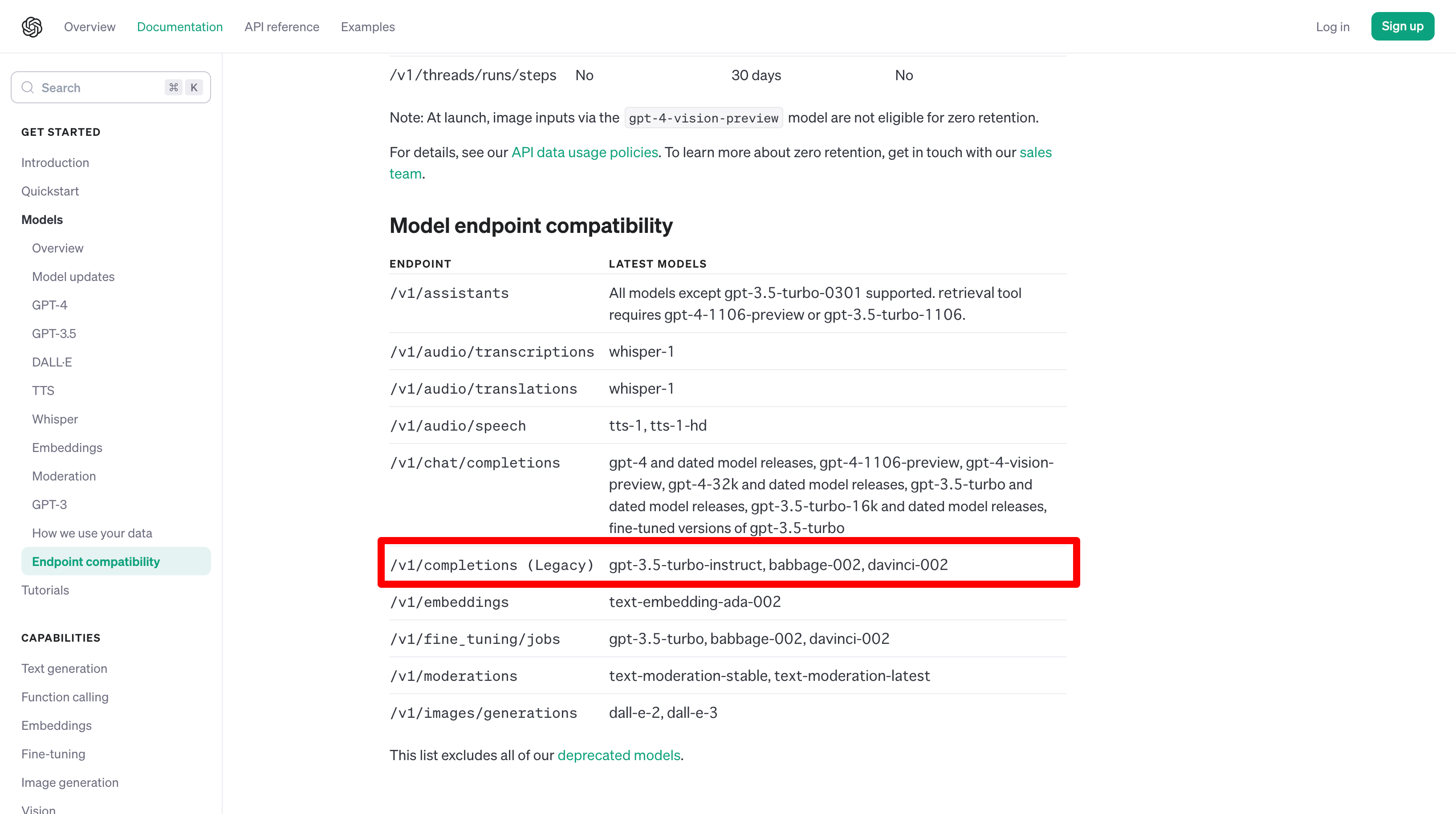
最新の情報は公式サイトを参照。
【②新しいモデル】Chatのパラメータ
モデル「gpt-3.5-turbo」などで使うパラメータ。
エンドポイントはhttps://api.openai.com/v1/chat/completionsを指定する。
| パラメーター名 | データ型 | 必須/任意 | デフォルト値 | 説明 |
|---|---|---|---|---|
| model | 文字列 | 必須 | --- | 使用するモデル名。(*1) |
| message | 配列 | 必須 | --- | チャットの文章。配列の形式は後述。 |
| temperature | 数値 | 任意 | 1(ブラウザ上のChatGPTは0.7) | 回答のランダム度合いを0〜1の間で指定。値が高いほど多様な単語が選ばれる。 |
| top_p | 数値 | 任意 | 1(ブラウザ上のChatGPTは0.9~0.95) | 回答の正確性を0〜1の間で指定。値が小さいほど、正確になる。temperatureパラメーターとどちらかのみ指定可能。 |
| n | 整数 | 任意 | 1 | 生成する回答の数。 |
| stream | 論理型 | 任意 | false | true:逐次レスポンスを受け取る。(前回のレスポンスとの差分だけ受け取る) false:すべて回答が終わってからレスポンスを受け取る。(すべてのレスポンスを受け取る) |
| stop | 文字列 | 配列 | 任意 | null | 回答を停止する単語を最大4つまで指定。(特定の単語が出たときに回答を強制停止できる) |
| max_tokens | 整数 | 任意 | 4096 - 入力トークン数 | 回答文章のトークンの最大数。 |
| presence_penalty | 数値 | 任意 | 0 | 同じ単語を使った場合のペナルティ(-2.0〜2.0)。値が高いほどペナルティが重く同じ単語は使わない。 |
| frequency_penalty | 数値 | 任意 | 0 | presence_penaltyとほぼ同じ。こちらは同じ単語を繰り返すほどペナルティが重くなる(2回程度の繰り返しはOKだが、何回も繰り返されるのが嫌なときに使えそう)。 |
| logit_bias | 配列 | 任意 | null | 特定の単語の出現頻度(-100〜100)を指定する。 -100:ほぼ一切出現しない。 -1:少し出現しづらい。 1:少し出現しやすい 100:ほぼ必ず出現する |
| user | 文字列 | 任意 | null | エンドユーザーを一意に識別するための文字列。悪用の防止に使える。 |
(*1)指定できるモデル一覧
公式サイトにモデル一覧が記載されている。
/v1/completionsの行を参照。
(2023年11月7日現在の公式サイト)
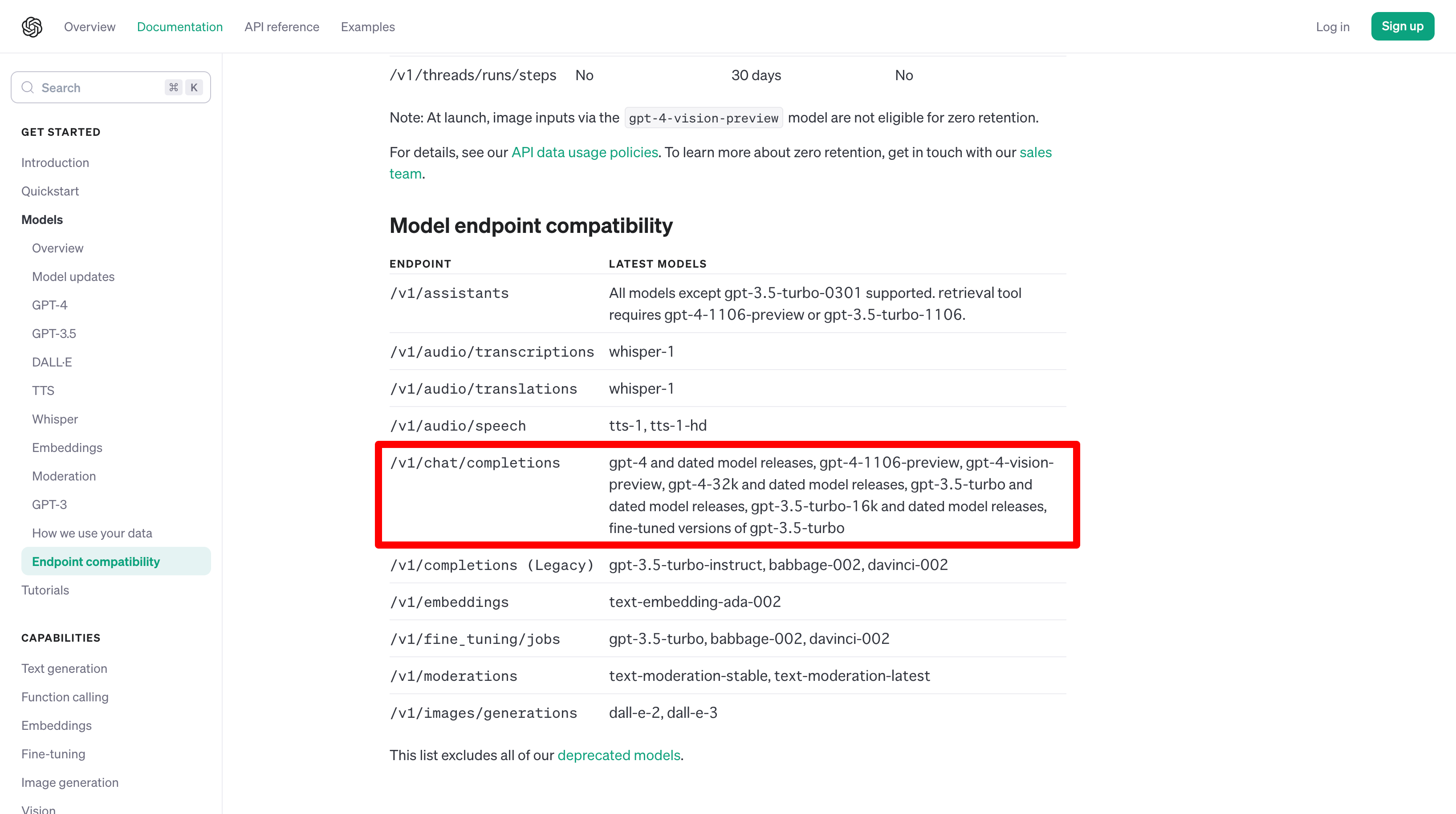
最新の情報は公式サイトを参照。
よく使うリクエスト
パラメータはいきなりすべて理解する必要はない。
ここではよく使うパラメータを解説する。
必須の情報は以下の4つ。
✅エンドポイント
APIにアクセスするためのURLが必要。
URLはモデルによって異なる。
→ChatモデルのURL:https://api.openai.com/v1/chat/completions
各モデルのURLは以下を参照。
✅APIキー
OpenAIのAPIキーが必要(先ほど取得済み)。
→リクエストヘッダーの中のAuthorizationパラメータに指定する。
※先頭にBearerをつける決まりがある。
"Authorization" : "Bearer [APIキー]"✅モデルの指定
どの機械学習モデルを使用するか?が必要。
→リクエストボディの中のmodelパラメータに指定する。
"model" : "gpt-3.5-turbo"✅質問内容
ChatGPTにどのような質問をするか?が必要。
→リクエストボディの中のmessagesパラメータ(配列)に指定する。
roleに役割、contentに質問文を指定する。
【補足】roleに指定できる値
| Roleの値 | 説明 |
|---|---|
system | ChatGPTに役割を与えることができる。 配列の先頭に設定する。 |
user | 質問文。 |
assistant | 回答文。 |
一般的に以下の流れで指定する。
1回目:system
2回目:user
3回目:assistant
4回目:user
5回目:assistant
…
例:単発の質問
messages : [
// システム設定(最初に役割を設定しておく)
{"role": "system", "content": "You are a helpful assistant."},
// 質問
{"role": "user", "content": "Who won the world series in 2020?"},
]例:文脈に沿った質問
messages : [
// システム設定(最初に役割を設定しておく)
{"role": "system", "content": "You are a helpful assistant."},
// 質問①(過去の質問)
{"role": "user", "content": "Who won the world series in 2020?"},
// 回答①(過去の回答)
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
// 質問②(今回の質問)
{"role": "user", "content": "Where was it played?"}
]必須ではないがよく使うオプションは以下の2つ。
✅トークン数制限
回答の長さを制限することができる。
→リクエストボディの中のmax_tokensパラメータに指定する
最大で4096まで指定できる(モデルによって異なる?)
✅回答のランダム度
回答の多様性(0〜1)を指定できる。
→リクエストボディの中のtemperatureパラメータに指定する
値が小さい → 回答が固定的になる。
値が大きい → 回答がランダムになる。
どんな値を指定すればいい?
パラメータの種類がたくさんあることはわかった!
でも実際のところどんな値を指定すればいいの…?😫💦
公式サイトでシチュエーション別のおすすめの値が解説されている!
→https://platform.openai.com/examples
プログラム上でリクエストする例
代表的なインターフェースからリクエストする例を4種類紹介する✅
curlでリクエストする例
curlでリクエストする簡単な例。
curl https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer APIキーを入れる" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [{"role": "user", "content": "Hello!"}]
}'PHPでリクエストする例
PHPでリクエストする簡単な例。
$url = "https://api.openai.com/v1/chat/completions";
$api_key = "APIキーを入れる";
// リクエストヘッダー
$headers = array(
"Content-Type: application/json",
"Authorization: Bearer $api_key"
);
// リクエストボディ
$data = array(
"model" => "gpt-3.5-turbo",
"messages" => [
[
"role" => "user",
"content" => "Hello!",
]
],
);
// cURLセッションの初期化
$ch = curl_init();
// cURLオプションの設定
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, json_encode($data));
curl_setopt($ch, CURLOPT_HTTPHEADER, $headers);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
// リクエストの送信と応答結果の取得
$ret = curl_exec($ch);
// エラーチェック
if($ret === false){
$error = 'Curl error: ' . curl_error($ch);
curl_close($ch);
echo $error;
}
// cURLセッションの終了
curl_close($ch);
// レスポンスを取得
$response = json_decode($ret);Pythonでリクエストする例
pythonでリクエストする簡単な例。
import os
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": "Hello!"}
]
)
print(completion.choices[0].message)node.jsでリクエストする例
node.jsでリクエストする簡単な例。
const { Configuration, OpenAIApi } = require("openai");
const configuration = new Configuration({
apiKey: process.env.OPENAI_API_KEY,
});
const openai = new OpenAIApi(configuration);
const completion = await openai.createChatCompletion({
model: "gpt-3.5-turbo",
messages: [{role: "user", content: "Hello world"}],
});
console.log(completion.data.choices[0].message);レスポンス
APIを使ったときに返ってくるレスポンスについて解説する。
レスポンスの概要
- APIに質問(リクエスト)した結果が、回答(レスポンス)として返ってくる。
- レスポンスはJSON形式。
- JSONの構造はモデルによって異なる。
早見表
レスポンスの内容はモデルによって異なる。
ここでは2種類のモデル「Completions」「Chat」のレスポンスを簡単に紹介する。
【①従来のモデル】Completionsのレスポンス
モデル「text-davinci-003」などのレスポンスについて解説する。
以下のリクエストを送った場合
{
"model" : "text-davinci-003",
"prompt" : "こんにちは",
}以下のようなレスポンスが返ってくる
{
// リクエストのID
"id": "cmpl-76pJjs53Hctu7Bz8TLpCHUdhNUfMj",
// 回答のタイプ
"object": "text_completion",
// 回答が生成された日時(UNIX)
"created": 1681861587,
// ChatGPTのモデル
"model": "text-davinci-003",
// 回答の内容
"choices": [
{
// 回答文
"text": "\n\nこんにちは!",
// 何番目の応答か
"index": 0,
// レスポンスで生成されたトークンの対数確率
"logprobs": null,
//
"finish_reason": "stop"
}
],
"usage": {
// 質問のトークン数
"prompt_tokens": 6,
// 回答のトークン数
"completion_tokens": 11,
// 合計トークン数
"total_tokens": 17
}
}【②新しいモデル】Chatのレスポンス
モデル「gpt-3.5-turbo」などのレスポンスについて解説する。
以下のリクエストを送った場合
{
"model" : "gpt-3.5-turbo",
"messages" : [
{
"role" : "system",
"content" : "あなたは挨拶ロボットです。"
},
{
"role" : "user",
"content" : "こんにちは"
}
]
}以下のようなレスポンスが返ってくる
{
// リクエストのID
"id": "chatcmpl-770JxrnXSDn2moJiVY9UTDCsZFrlL",
// 回答のタイプ
"object": "chat.completion",
// 回答が生成された日時(UNIX)
"created": 1681903885,
// ChatGPTのモデル
"model": "gpt-3.5-turbo-0301",
// トークン数
"usage": {
// 質問のトークン数
"prompt_tokens": 28,
// 回答のトークン数
"completion_tokens": 30,
// 合計トークン数
"total_tokens": 58
},
// 回答の内容
"choices": [
{
// 具体的なメッセージ
"message": {
// このメッセージの役割。3種類のどれか。
// ①system → 質問に役割を設定する。精度を高めるときに使う。
// ②usr → 質問文
// ③assistant → 回答文
"role": "assistant",
// 回答文
"content": "こんにちは!私は挨拶ロボットです。どのようなお手伝いができますか?"
},
// 回答が終了した理由。4種類のどれか。
// ①stop → 正常終了
// ②lengthmax_tokens → パラメータまたはトークンの制限により不完全な回答
// ③content_filter → コンテンツフィルターからのフラグにより回答が省略された
// ④null → 回答が進行中または不完全
"finish_reason": "stop",
// 何番目の応答か
"index": 0
}
]
}よく使うレスポンス
レスポンスはいきなりすべて理解する必要はない。
ここではよく使うレスポンスを解説する。
✅回答の内容
リクエストした質問の答えを取得するには?
→response['choices'][0]['message']['content']に回答が入っている。
さっきの例の以下の部分に回答が入っている
"choices": [
{
"message": {
"role": "assistant",
// 👇これが回答
"content": "こんにちは!私は挨拶ロボットです。どのようなお手伝いができますか?"
},
"finish_reason": "stop",
"index": 0
}
]【補足】なぜ0番目の要素?
response['choices'][0]['message']['content']を見ると[0]と決め打ちしているのが気になる。
[0]の意味は以下のとおり。
- 0番目の回答を指定している。
- リクエストのパラメータ
nを指定すると回答の数を増やせる。このときresponse['choices'][1]['message']['content']などが使える。 - 通常
n=1でリクエストするため[0]にアクセスすることがほとんど。
response['choices'][0]['message']['content']を扱えれば最低限のことはできる!注意点
APIは有料なので、適当に使うと高額請求の恐れもある。
どこに気をつければ安心か解説する。
APIキーを公開しない
当たり前だがAPIキーはかならず非公開にする。
誤ってGitで公開してしまわないよう注意する。
適切なモデルを使う
モデルによってAPI料金が異なる。
代表的なモデルの料金(2023/11/7時点)
| モデル | 料金(1000トークンあたり) |
|---|---|
| gpt-3.5-turbo-1106 | $0.001 |
| Davinci | $0.1200 |
最初にも載せたが、gpt-3.5-turbo-1106モデルの目安は以下のとおり。
| 使用トークン数 | 料金(ドル) | 料金(円) |
|---|---|---|
| 1,000 | 0.001 | 0.15 |
| 10,000 | 0.01 | 1.5 |
| 100,000 | 0.1 | 15 |
| 500,000 | 0.5 | 75 |
| 1,000,000 | 1.0 | 150 |
最新の情報は以下を参照。
過去のメッセージを含めすぎない
Chatモデルでは「質問内容」に過去の質問や回答を含めることができる。
これは回答の精度を上げたり、会話の流れを汲むために便利な機能だが、その分消費するトークン数が増えてしまう。
日本語はトークン消費が多い
日本語と英語でトークンの数え方が異なる✅
| 言語 | 1トークン |
|---|---|
| 英語 | 1単語 |
| 日本語 | 1文字 |
※ただし漢字は1文字で2〜3トークン消費するので注意。
翻訳してからAPIを使うのもアリ!
質問を簡潔にする
質問を簡潔にすることでトークン数を減らすことができる。
質問を開発者が設定するような場合は、簡潔な質問にしておくといい。
回答を簡潔にする
回答を簡潔にしてもらうことでトークン数を減らすことができる。
可能であれば質問の中に「〇〇文字以内で教えて」などの指定をしておくといい。
余計なリクエストをしない
リクエストパラメータの中にはトークン数を増加させてしまうものがある。
具体的には以下は注意が必要。
| パラメーター名 | 説明 | デフォルト値 |
|---|---|---|
| n | 回答の数 | 1 |
| best_of | 回答を生成する数 | 1 |
これらは回答を複数生成するため、1増やすごとレスポンスのトークン数が2倍、3倍…と増えていく。
利用金額の上限設定をしておく
以下のページで利用金額の上限を設定できる。
(クレジットカード登録後のみ設定可能)
参考サイト




